
博客
技术焦点:集群管理软件
随着HPC系统的复杂性不断提高,这些系统的有效管理对于最大化科学计算的投资回报变得越来越重要。
确保有效利用集群是一项复杂的工作。但是,采用最新软件可以减轻支持 HPC 集群的负担,减少管理资源所需的人数,或者通过更有效地利用资源来完成更多的科学和工程。
群集管理软件的可用选项与可以部署它们的计算系统类型一样多种多样。无论您是由于预算限制而利用开源软件的学术机构,还是通过额外支持和维护支付软件费用的商业公司,选择合适的软件包都可以节省关键资源。
但是,有几种久经考验的方法非常适合 HPC 和 AI 框架,如下所述。其中许多工具在开放和商业许可证中可用,具体取决于所需的支持级别。
可用产品
联泰集群拥有安装高性能计算软件堆栈的经验。联泰集群提供专有的集群管理软件 LtHCS高性能计算集群管理系统。

联泰集群 LtHCS 集群管理软件标配所有 HPC 集群及其标准服务包。LtHCS 软件与大多数 Linux 发行版兼容,并且在集群的生命周期内受支持。
英伟达 Bright 集群管理器为边缘、数据中心和多/混合云环境中的异构高性能计算 (HPC) 和 AI 服务器集群提供快速部署和端到端管理。它可以自动配置和管理大小从几个节点到数十万个节点的集群,支持基于 CPU 和 Nvidia GPU 加速的系统,并支持与 Kubernetes 的编排。

Nvidia Bright 集群管理器允许您在裸机上部署完整的 Linux 集群,并可靠地管理它们,从边缘到核心再到云。Nvidia Bright 集群管理器为高性能计算 (HPC) 的新时代提供集群管理解决方案,将配置、监控和管理功能结合在一个工具中,涵盖 Linux 集群的整个生命周期。
Advanced Clustering Technologies 设计了 ClusterVisor,使您能够轻松部署 HPC 集群,并使用单个 GUI 管理从硬件和操作系统到软件和网络的所有内容。
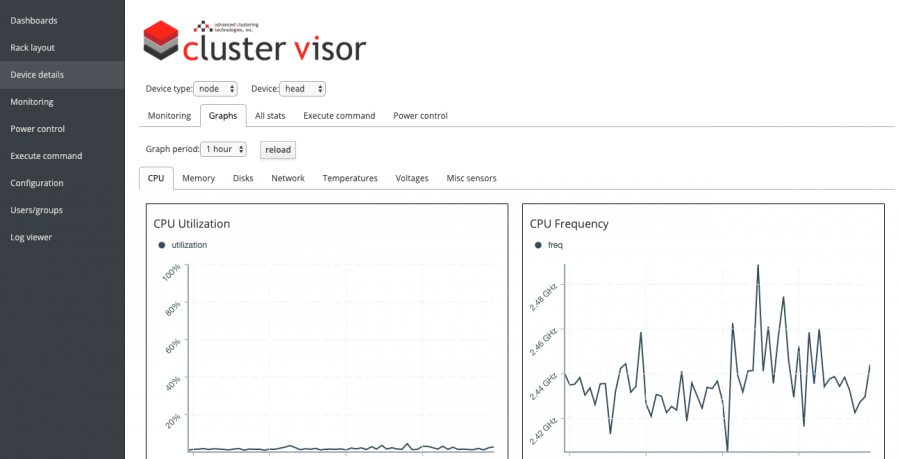
他们功能齐全的 ClusterVisor 工具为您提供了随着时间的推移管理和更改集群所需的一切。ClusterVisor 是高度可定制的,以确保您可以以最适合您的方式管理集群和组织数据。
ACT 的 eQUEUE 是一种软件解决方案,允许系统管理员创建易于使用的基于Web的作业提交表单。它旨在通过将更多用户引入群集来提高群集利用率,这些用户通常由于向群集提交作业的复杂性而远离群集。没有必要学习Linux或脚本。最终用户只需将其数据输入预定义字段,作业现在就在集群的队列中运行。
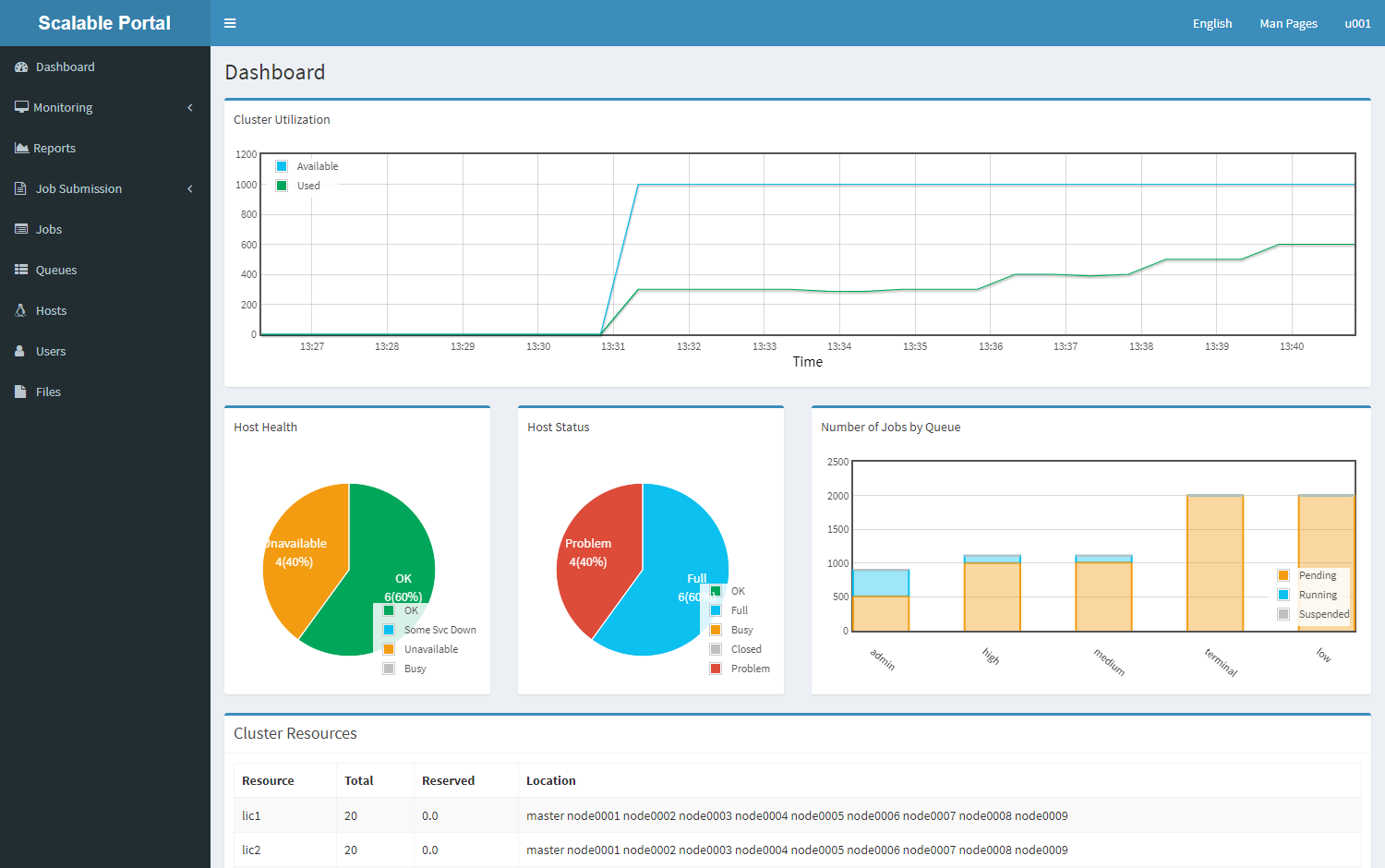
HPC Scalable 的 The Scalable Cube 是企业就绪、受支持的开源工作负载调度程序发行版,支持各种 HPC 和分析应用程序。无论是部署在现场、虚拟基础架构上还是云中,客户都可以利用 HPC Scalable 提供的高质量支持服务,帮助确保成功管理其 HPC 工作负载。
Microsoft 提供的 Azure 高性能计算 (HPC) 是一套完整的计算、网络和存储资源,与 HPC 应用程序的工作负载编排服务集成。借助专门构建的 HPC 基础结构、解决方案和优化的应用程序服务,与本地选项相比,Azure 提供了具有竞争力的性价比,并具有额外的高性能计算优势。此外,Azure 还包括下一代机器学习工具,可推动更智能的模拟并实现智能决策。
Adaptive Computing 的 Moab HPC Suite 是一个工作负载和资源编排平台,可大规模自动调度、管理、监控和报告HPC工作负载。其获得专利的智能引擎使用多维策略和先进的未来建模来优化不同资源的工作负载启动和运行时间。
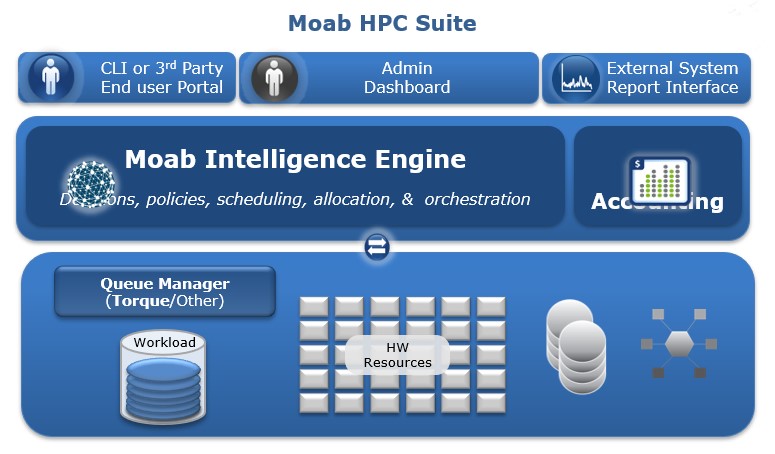
这些策略平衡了高利用率和吞吐量目标与相互竞争的工作负载优先级和 SLA 要求,从而在更短的时间内以正确的优先级顺序完成更多的工作。Moab HPC Suite 优化了 HPC 系统的价值和可用性,同时降低了管理成本和复杂性。
Omnia 是一种部署工具,用于将运行基于标准 RPM 的 Linux 操作系统映像的 Dell EMC PowerEdge 服务器配置为能够支持HPC,AI和数据分析工作负载的集群。它使用 Slurm、Kubernetes 和其他软件包来管理作业,并在同一融合解决方案上运行不同的工作负载。它是 Ansible 剧本的集合,是开源的,并且不断扩展以实现全面的工作负载。

Altair PBS Professional 是一款快速、功能强大的工作负载管理器,旨在提高生产力、优化利用率和效率,并简化集群、云和超级计算机的管理 - 从最大的 HPC 工作负载到数百万个小型高吞吐量作业。PBS Professional 可自动执行作业计划、管理、监控和报告,是复杂的 Top500 系统以及小型集群的可靠解决方案。

Altair 的 Univa 网格引擎是一个分布式资源管理系统,用于优化数千个数据中心的工作负载和资源,提高性能并提高生产力和效率。Grid Engine 通过优化应用程序、容器和服务的吞吐量和性能,同时最大限度地利用本地、混合和云基础架构之间的共享计算资源,帮助组织提高投资回报率并更快地交付结果。

Google 的 Kubernetes 是一个开源系统,用于自动化容器化应用程序的部署,扩展和管理。它将组成应用程序的容器分组到逻辑单元中,以便于管理和发现。Kubernetes 建立在 Google 运行生产工作负载的 15 年经验之上,并结合了社区的最佳想法和实践。

IBM Spectrum LSF(“LSF”,负载共享设施的缩写)软件是一种企业级软件,旨在跨现有异构 IT 资源分配工作。这将创建一个共享、可扩展且容错的基础架构,从而提供更快、更可靠的工作负载性能并降低成本。LSF 平衡负载和分配资源,并提供对这些资源的访问。

LSF 提供了一个资源管理框架,该框架可以满足您的作业需求,查找运行作业的最佳资源,并监视其进度。作业始终根据主机负载和站点策略运行。
Slurm 是一个开源、容错且高度可扩展的集群管理和作业调度系统,适用于大型和小型 Linux 集群。Slurm 的操作不需要内核修改,并且相对独立。

作为集群工作负载管理器,Slurm 具有三个关键功能。首先,它将对资源(计算节点)的独占和/或非独占访问权限分配给用户一段时间,以便他们可以执行工作。其次,它提供了一个框架,用于在分配的节点集上启动、执行和监视工作(通常是并行作业)。最后,它通过管理待处理工作的队列来仲裁资源争用。




相关贴子
-
 技术分享
技术分享高效扩展 Polars 的 GPU Parquet 读取器
2025.04.11 29分钟阅读 -
 技术分享
技术分享Ollama 与 vLLM 深度对比:大模型部署方案如何选型
2026.05.18 70分钟阅读 -
 技术分享
技术分享YOLOv8 目标检测设置教程
2025.05.30 47分钟阅读