
博客
NVIDIA 发布 DGX GH200:首个百兆级字节的GPU内存系统
May 28, 2023
By Pradyumna Desale

在COMPUTEX 2023上,NVIDIA发布了NVIDIA DGX GH200,这标志着GPU加速计算的又一突破,为要求最严苛的巨型AI工作负载提供动力。除了描述NVIDIA DGX GH200架构的关键方面之外,本文还讨论了NVIDIA Base Command如何实现快速部署、加速用户入职以及简化系统管理。
在过去7年中,GPU的统一内存编程模型一直是复杂加速计算应用取得各种突破的基石。2016年,NVIDIA推出了NVLink技术和CUDA-6的统一内存编程模型,旨在增加GPU加速工作负载的可用内存。
从那时起,每个DGX系统的核心都是一个位于底板上的GPU综合体,通过NVLink互联,其中每个GPU都能以NVLink速度访问对方的内存。许多这样的带有GPU复合体的DGX通过高速网络互连,形成更大的超级计算机,如英伟达Selene超级计算机。然而,一类新兴的巨型、万亿级参数的人工智能模型要么需要几个月的时间来训练,要么即使在当今最好的超级计算机上也无法解决。
为了让那些需要先进平台的科学家能够解决这些非同寻常的挑战,NVIDIA将NVIDIA Grace Hopper超级芯片与NVLink交换系统配对,在NVIDIA DGX GH200系统中联合了多达256颗GPU。在DGX GH200系统中,144兆字节的内存将通过NVLink高速访问GPU共享内存编程模型。
与单个NVIDIA DGX A100 320 GB系统相比,NVIDIA DGX GH200通过NVLink为GPU共享内存编程模型提供了近500倍的内存,形成一个巨大的数据中心大小的GPU。NVIDIA DGX GH200是第一台通过NVLink为GPU访问的内存突破100兆字节的超级计算机。
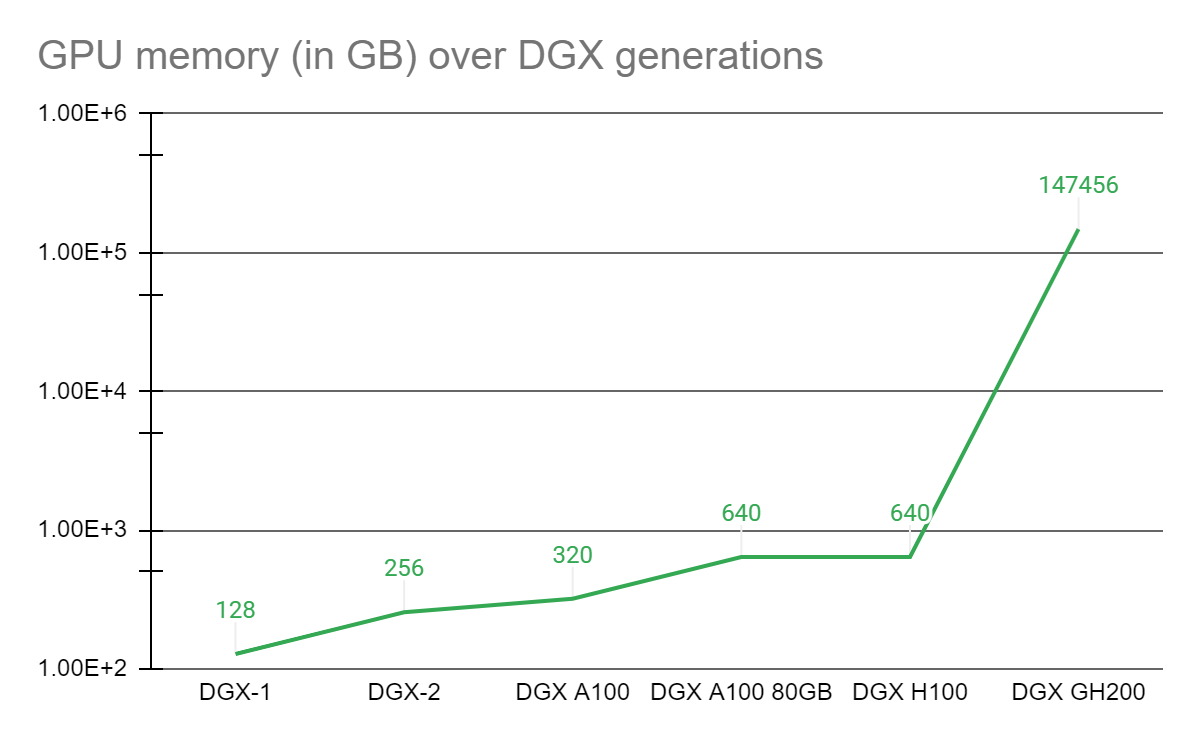
图1. 作为NVLink进展的结果,GPU内存的收益
NVIDIA DGX GH200系统架构
NVIDIA Grace Hopper超级芯片和NVLink Switch系统是NVIDIA DGX GH200架构的构建模块。NVIDIA Grace Hopper超级芯片利用NVIDIA NVLink-C2C将Grace和Hopper架构结合起来,提供了一个CPU+GPU的连贯内存模型。由第四代NVLink技术驱动的NVLink Switch系统将NVLink连接扩展到整个超级芯片,从而创造出一个无缝、高带宽的多GPU系统。
NVIDIA DGX GH200中的每个NVIDIA Grace Hopper超级芯片都拥有480 GB的LPDDR5 CPU内存,与DDR5相比,每GB的功率只有八分之一,而且还有96 GB的快速HBM3。NVIDIA Grace CPU和Hopper GPU通过NVLink-C2C互连,提供比PCIe Gen5多7倍的带宽,而功率仅为五分之一。
NVLink Switch系统形成了一个两级、无阻塞、胖树状的NVLink结构,可以完全连接DGX GH200系统中的256颗Grace Hopper超级芯片。DGX GH200中的每个GPU都可以以900 GBps的速度访问其他GPU的内存和所有NVIDIA Grace CPU的扩展GPU内存。
托管Grace Hopper超级芯片的计算底板使用第一层NVLink结构的定制电缆线束连接到NVLink Switch系统。LinkX电缆扩展了NVLink结构第二层的连接。
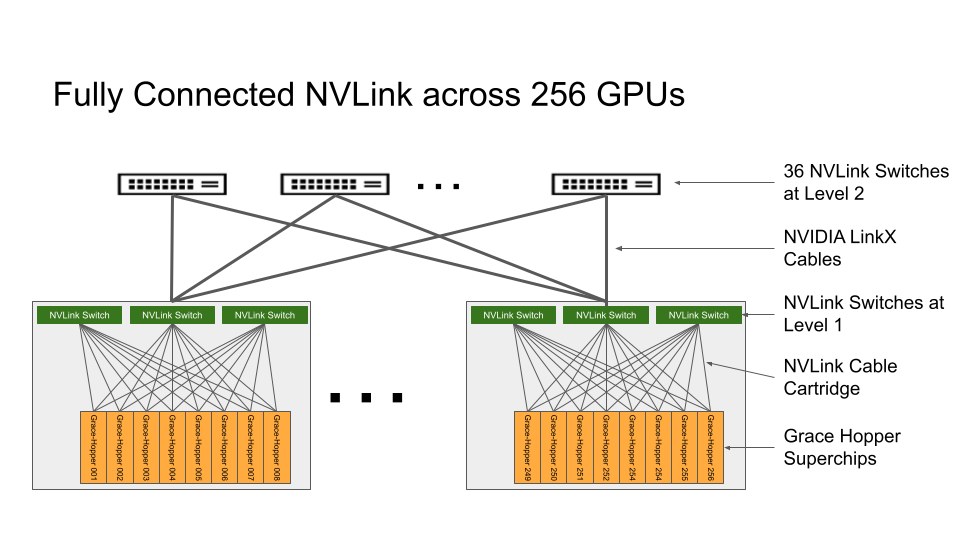
图2. 由256个GPU组成的NVIDIA DGX GH200上完全连接的NVLink交换系统的拓扑结构
在DGX GH200系统中,GPU线程可以通过NVLink页面表从NVLink网络中的其他Grace Hopper超级芯片中寻址对等的HBM3和LPDDR5X内存。英伟达Magnum IO加速库优化了GPU的通信效率,增强了所有256个GPU的应用扩展能力。
DGX GH200中的每个Grace Hopper超级芯片都搭配了一个NVIDIA ConnectX-7网络适配器和一个NVIDIA BlueField-3网卡。DGX GH200拥有128 TBps的双节带宽和230.4 TFLOPS的NVIDIA SHARP网络内计算,可以加速人工智能中常用的集体操作,并通过减少集体操作的通信开销,将NVLink网络系统的有效带宽提高一倍。
对于超过256个GPU的扩展,ConnectX-7适配器可以将多个DGX GH200系统互连起来,扩展成一个更大的解决方案。BlueField-3 DPU的力量将任何企业计算环境转化为安全和加速的虚拟私有云,使企业能够在安全的多用户环境中运行应用工作负载。
目标场景和性能优势
GPU内存的代际飞跃极大地提高了受限于GPU内存大小的AI和HPC应用的性能。许多主流的AI和HPC工作负载可以完全驻留在单个NVIDIA DGX H100的聚合GPU内存中。对于此类工作负载,DGX H100是性能最高效的训练解决方案。
其他工作负载--例如具有TB级嵌入式表格的深度学习推荐模型(DLRM)、TB级图形神经网络训练模型或大型数据分析工作负载--使用DGX GH200可实现4倍至7倍的速度提升。这表明,对于需要大量内存的更高级的人工智能和HPC模型来说,DGX GH200是一个更好的解决方案,适合GPU共享内存编程。
在NVIDIA Grace Hopper超级芯片架构白皮书中详细描述了提速的机制。

图3. 巨型内存AI工作负载的性能比较
专为最苛刻的工作负载而设计
整个DGX GH200的每一个组件都是为了最大限度地减少瓶颈,同时最大限度地提高关键工作负载的网络性能,并充分利用所有扩展的硬件能力。其结果是线性可扩展性和对大量共享内存空间的高利用率。
为了最大限度地发挥这一先进系统的作用,NVIDIA还设计了一个极高速的存储结构,使其能够以峰值容量运行,并以并行的方式处理各种数据类型(文本、表格数据、音频和视频),而且性能坚定。
全栈式NVIDIA解决方案
DGX GH200配备了NVIDIA Base Command,其中包括针对人工智能工作负载优化的操作系统、集群管理器、加速计算的库、存储和网络基础设施都是针对DGX GH200系统架构优化的。
DGX GH200还包括NVIDIA AI Enterprise,提供一套经过优化的软件和框架,以简化AI开发和部署。这一全栈式解决方案使客户能够专注于创新,而不必为管理其IT基础设施而担忧。

图4. NVIDIA DGX GH200 AI超级计算机全栈包括NVIDIA Base Command和NVIDIA AI Enterprise
为超大的人工智能和HPC工作负载增压
英伟达公司正在努力使DGX GH200在今年年底上市。英伟达渴望提供这台令人难以置信的首款超级计算机,并使你能够在解决当今最大的人工智能和高性能计算挑战方面进行创新和追求自己的激情。了解更多信息。
来源:英伟达博客





相关贴子
-
 新闻
新闻九年磨一剑!中国超算「灵晟」登顶全球第一,联泰集群全栈方案筑牢自主算力底座
2026.06.26 17分钟阅读 -
 新闻
新闻2 月 28 日 | 联泰集群将携“灵台”亮相第四届北京人工智能产业创新发展大会,科研智能体平台赋能 AI + 科研
2026.02.16 6分钟阅读 -
 新闻
新闻DeepSeek 都打 2.5 折了,你的算力底座还在“高消费”吗?
2026.04.30 6分钟阅读