
博客
为人工智能训练和推理扩展存储的技巧
GPU 在扩展 AI 方面有很多好处,从更快的模型训练到 GPU 加速的欺诈检测。在规划人工智能模型和部署的应用程序时,必须考虑到可扩展性的挑战,特别是性能和存储。
无论使用情况如何,人工智能解决方案都有四个共同的要素:
1.训练模型
2.推理应用
3.数据存储
4.加速计算
在这些要素中,数据存储往往是在规划过程中最被忽视的。为什么?因为数据存储需求是随着时间的推移发生变化的,在创建和部署人工智能解决方案时,并不总是会被考虑。大多数人工智能部署的要求通过 POC 或测试环境迅速确认。
然而,挑战在于,POCs 往往解决一个单一的时间点。培训或推理部署可能存在几个月或几年。因为许多公司迅速扩大其人工智能项目的范围,基础设施也必须扩展以适应不断增长的模型和数据集。
这篇博客解释了如何提前规划和扩展训练和推理的数据存储。
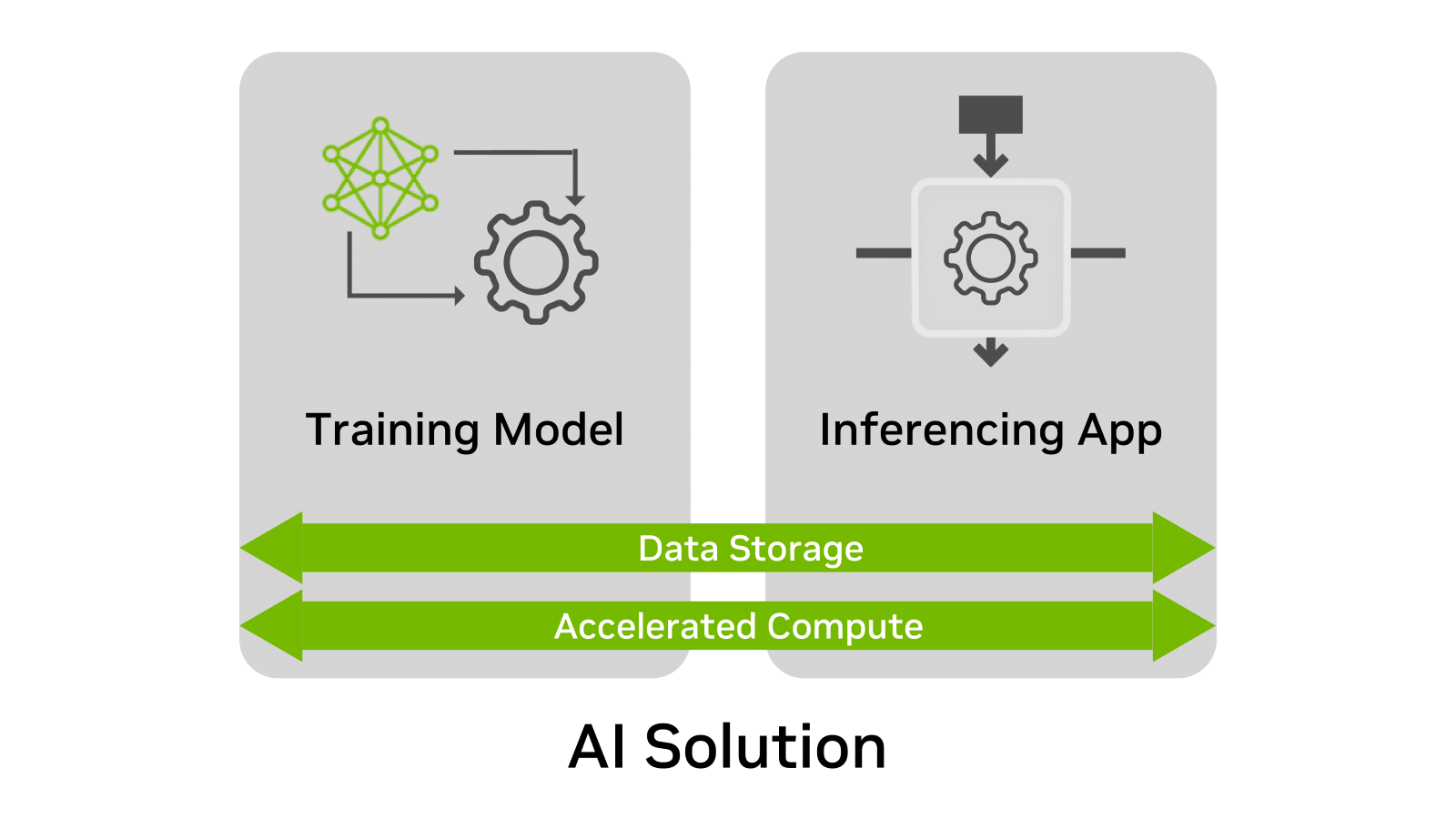
图1. 训练和推理的基础
用于人工智能的数据存储层次结构
要想开始,请先了解人工智能的数据存储层次,其中包括 GPU 内存、数据结构和存储设备(图2)。
一般来说,你在存储层次中的位置越高,存储性能就越快,特别是延迟。在本讨论中,存储被定义为在电源开启或关闭时存储数据的任何东西,包括内存。
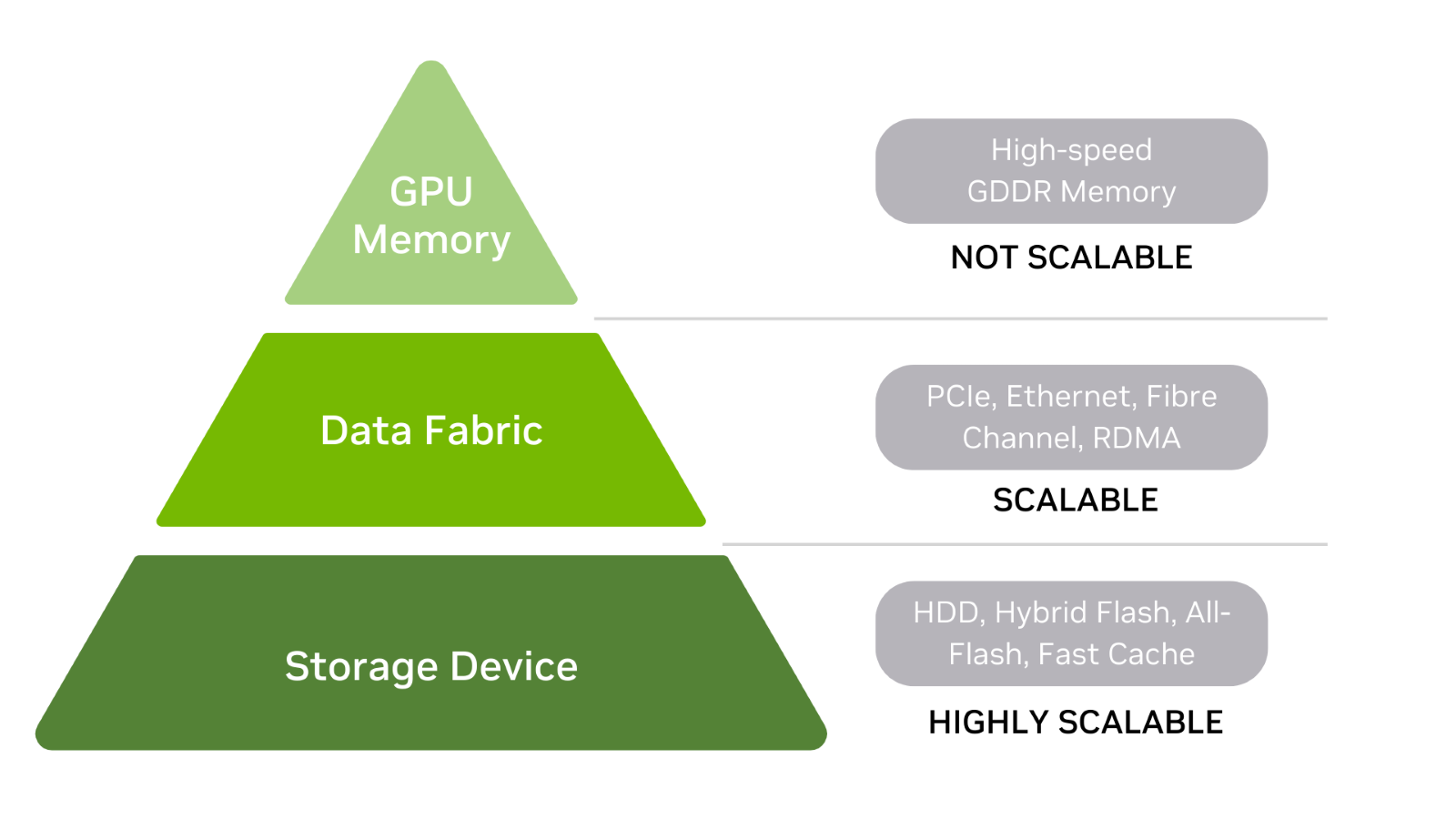
图2. 人工智能的数据存储层次结构
存储设备
硬盘和闪存驱动器是存储层次的基础。也有混合阵列,它们是各自的组合。硬盘可能以快速缓存层为前端,而全闪存阵列可能使用存储级内存(SCM)来提高读取性能。
当大型数据集加载到 GPU 内存的时间很重要时,快速存储很有用。当需要训练一个不再适合存储设备的模型时,很容易扩展存储容量。也可能是必须存储多个数据集--这是拥有可扩展存储的另一个原因。
数据结构
在层次结构的中间,数据结构被用来连接存储设备和 GPU 内存。
这一层包括:
- PCIe 总线
- 网卡
- DPU
- 数据通路中的任何其他卡存储和 GPU 内存之间。
为了简单起见,结构可以简单地被看作是存储设备和 GPU 内存之间的一个直通数据层。
GPU内存
由于 GPU 内存速度快且直接与 GPU 相连,当整个模型位于内存中时,训练数据集的处理速度很快。CPU 内存也在层次结构的顶端,仅次于 GPU 内存。
另外,模型数据可以分多批发送到 GPU 内存。大的 GPU 内存会导致更少的批次和更快的训练时间。如果 GPU 为模型或数据集的任何部分传送数据结构到内部或外部存储,将活动交换到磁盘会大大降低训练性能。
请记住,虽然存储设备和数据结构可以扩展,但 GPU 内存是固定的。这意味着 GPU 内存是配置给 GPU 的,内存大小不能升级以支持更大的训练模型和数据集。
如果制造商支持,例如通过英伟达 NVLink,原始 GPU 可以使用新增 GPU 的内存。然而,并不是所有的系统都能容纳第二个 GPU 和增加内存的可能性。
最终,部署计划应包括一个内存远远超过当前需求的 GPU 。在未来解决内存不足的问题可能会很昂贵。
为推理扩大存储规模时的考虑因素
推理是人工智能解决方案的价值传递所在。出于这个原因,需要有效的存储。
为了确保推理的存储是可扩展的,请考虑以下因素:
- 纵向扩展与横向扩展
- 无缝升级
- 实时要求
纵向扩展与水平扩展
存储的可扩展性并不仅仅是以容量来衡量。它也是以性能来衡量的。真正的扩展性确保当容量和性能要求增加时,存储系统会根据需要提供更多的容量和性能。

图 3. 单人驾驶的三轮车的性能由乘客的数量决定。三轮车是一个纵向扩展的例子,因为乘客的数量可以变化(来源:iStock/grafficx)。
让我们来研究一个与纵向扩展的现实世界的例子。在旧金山旅游区有几十辆三轮车。一个骑自行车的人或司机为三轮车提供动力,三轮车的乘客人数为2人、4人甚至6人。
在只有一名乘客的情况下,司机可以快速蹬车,更快地到达目的地,并更快地寻找新的乘客。装载更多乘客的三轮车会导致加速变慢,最高速度降低,并且一天的行程减少。三轮车是一种纵向扩展的机器。
你可以很容易地增加容量,但在性能上没有相应的增加,因为你被限制在一个司机的力量。对于横向扩展的机器,每增加一个乘客,就有一个额外的司机为三轮车提供动力。当功率和容量线性增加时,性能永远不会成为一个瓶颈。
对于推理来说,容量和性能的真正扩展是关键。推理服务器可以随着时间的推移存储大量的数据。存储的读写性能必须扩展,以防止推理结果的延迟。
但是,随着推理应用的执行,语音、图像、客户资料和其他数据被写入磁盘,存储容量也必须扩展。此外,还需要有效地存储再训练数据,以便反馈到模型中。
无缝升级
某些推理应用不能很好地容忍停机。例如,什么是关闭网店的欺诈检测的最佳时机?当你禁用网店推荐引擎以升级存储容量或存储性能时,会有什么损失的订单?
可能受到维护升级影响的推理应用的清单是非常广泛的,例子包括:
- 用于客户服务的对话式AI应用。
- 对视频流进行24/7分析,以获得智能洞察力。
- 关键的图像识别应用。
除非推理能够容忍维护窗口,否则扩展容量和性能会成为一个挑战。在致力于特定的存储部署之前,最好先考虑一下存储升级和可用性方案。
实时要求
作为一个实时推理的例子,考虑一下在线交易的欺诈检测。推理应用正在寻找显示出不可接受的风险的异常行为和交易概况。在用户等待交易批准时,必须在几分之一秒内做出数百项决定。低延迟存储和高性能数据结构连接是实时交易的关键,特别是当风险参数必须快速从存储中检索时。
亚毫秒的存储性能是某些实时应用程序的起点,这些应用程序受益于存储和 GPU 内存之间的高性能途径。英伟达利用 RDMA 协议来加速从存储到 vRAM 的传输,其功能称为英伟达 GPUDirect Storage。这可以缩短 GPU 对实时需要的存储数据(如风险概况数据)的检索时间。检索到的概况和风险数据点以后可以重新进行分析,以提高准确性。
NVIDIA GPUDirect 技术支持 GPU 内存和本地 NVMe 存储之间的 DMA 直接数据通路交易,或者通过 NVMe-oF进行远程存储。
解决疏忽问题
在规划过程中往往有改进的余地。训练和推理的一些常见的存储相关的疏忽包括可扩展性、性能、可用性和成本。
在训练和推理过程中,有一些方法可以避免这种情况。
训练:
- 始终使用远远超过当前要求的 GPU 内存进行部署。
- 始终考虑未来模型和数据集的大小,因为 GPU 内存是不可扩展的。
推理:
- 当预期性能和容量都会随着时间的推移而增长时,选择横向扩展存储。
- 选择支持无缝升级的存储,特别是对于那些很少或没有提供维护窗口的应用程序。
- 未来支持实时推理应用的存储升级可能不可能或不实际。在最初的 GPU、存储和结构部署之前做出这些决定。
主要收获
应尽早以整体的方式解决存储的扩展问题。这包括容量、性能、网络硬件和数据传输协议。最重要的是,确保充足的 GPU 资源,因为如果不这样做,就会否定所有其他的训练和推理工作。
关于作者

About André Franklin André Franklin 是英伟达公司数据科学营销团队的一员,主要负责跨英伟达驱动的工作站和服务器的基础设施解决方案。他在多个企业解决方案方面拥有广泛的经验,包括 NetApp、惠普企业和 Nimble 存储阵列与预测分析。
本文摘自英伟达开发者博客。





相关贴子
-
 存储
存储7PB 容量 + 8 倍提速!联泰集群助力三甲医院搭建心血管病数据存储 “超级大脑”
2026.01.30 21分钟阅读 -
 存储
存储什么是 EDSFF?数据中心高速存储的 “四大金刚”(E1.S/E1.L/E3.S/E3.L)详解
2026.01.30 53分钟阅读 -
 存储
存储GDDR 和 DDR 内存之间有什么区别?
2024.02.06 21分钟阅读