
博客
Single Root、Dual Root、直连,分别如何访问 HPC 服务器中的 PCIe
 了解 PCIe 体系结构,最大限度提高 GPU 服务器性能
了解 PCIe 体系结构,最大限度提高 GPU 服务器性能
与传统的纯 CPU 服务器相比,GPU 已经成为 AI 和 HPC 应用程序在高性能计算应用的实际解决方案。在这些系统上可以执行广泛的应用程序,利用 GPU 应用程序的性能提高已被广泛证实。时至今日,新技术和应用程序正在开发中,以利用和优化日益强大的 GPU 性能。
虽然以 GPU 为中心的服务器包含单 CPU 或双 CPU 以及最多 10 个 PCIe GPU,但系统的架构可能会影响服务器应用程序的速度和灵活性。有三种方法可以设计 GPU 服务器,从而为各种工作负载提供更优化的系统。在选择 GPU 服务器时, CPU 和 GPU 之间的数据流至关重要。
PCIe GPU 访问选项
联泰集群 GPU 服务器专为分子动力学、人工智能和深度学习而设计,满足其各种 HPC 工作负载大量计算的需求。虽然 1:1 的 CPU 与 GPU 比率在台式机、工作站和服务器中很常见,但通常,具有挑战性的高计算工作负载需要设计用于多 GPU 配置的高性能 GPU 服务器。
GPU 服务器有两种通用架构:
· 基于 PCIe 的服务器:GPU 服务器,最多可提供 8 个或 10 个用于 GPU 的 PCIe 插槽。
· 基于 SXM/OAM 的服务器:GPU 服务器,其中 GPU 安装并集成在主板上,并且只有 1 个 PCIe 连接到 CPU。
GPU 服务器也有双 CPU 插槽配置的选项。这两个 CPU 分别通过名为 UPI 和 xGMI 的高速通信路径进行通信,用于 Intel 和 AMD 服务器。
独特的系统体系结构 - PCIe 的连接方式
深入研究 PCIe 服务器,有 3 种不同的系统架构可用于各种工作负载:
· Single Root
· Dual Root
· 直连
Single Root 结构 - 1 个 CPU,2 个 PCIe 交换机
Single Root 体系结构非常适合驻留在单个 GPU 上但需要访问多个 GPU 的应用程序。Single Root 系统专用于其中一个 CPU(如果适用,则为两个 CPU 中的一个)来管理与 GPU 的所有通信。

如图所示,与 GPU 通信的CPU使用称为 PLX 的 PCI 交换机。每个 PLX 交换机通过 2 个 PCIe x16 通道连接到 CPU,然后可以与最多 4 或 5 个 GPU 通信,单个服务器中最多 10 个 GPU。
由于所有计算都连接到一个 CPU 上,因此 Single Root 架构更加简化,延迟更低,适用于大多数应用程序。Single Root 系统是为大多数计算以 GPU 为中心、对等通信不重要的应用程序量身定制的。应用示例包括 AMBER 分子动力学和其他模拟类型的工作负载。
Dual Root 结构 - 2 个 CPU,2 个 PCIe 交换机
Dual Root 设置通过 PLX 交换机将 CPU 连接到几个 GPU 和附加卡(AOC)。连接到 PLX 的 GPU 的分布不需要相等;分配给系统的工作负载可能不容易在两个 CPU 之间分配。
每个 CPU 可以通过 UPI/xGMI 相互通信,因此连接的 PCIe 设备的组合更灵活(一个 CPU 用于存储和网络,一个 CPU 用作计算)。然而,在大多数服务器配置中,硬件分配相等是常见的。
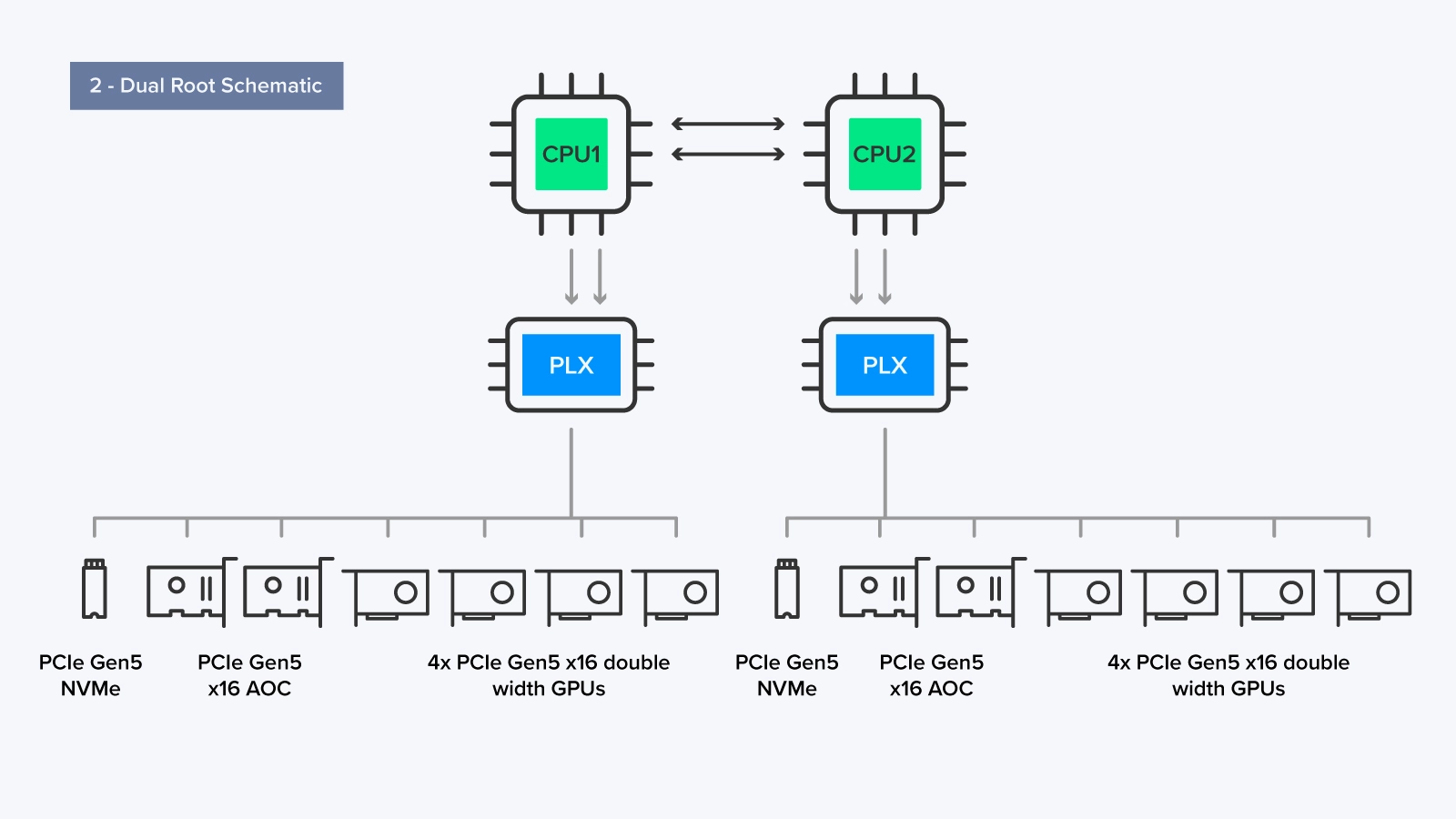
每个 CPU 通过其专用 PLX 交换机连接到 4 个 GPU、2 个 AOC 和 4 个 NVMe 存储驱动器,这是 Omniverse 环境工作负载的典型配置。AOC 可以是额外的存储、高速网卡等等。
对于需要在 CPU 和 GPU 处理能力之间取得平衡的应用程序,尤其是当工作负载之间的数据共享和通信至关重要时,Dual Root 服务器设置是有利的。在这种设置中,工作负载可以分配给每个 CPU,允许两个处理器利用各自的计算能力,然后在必要时促进它们之间的通信。应用程序示例包括深度学习培训、高性能计算(HPC)和工作负载,其中 CPU 和 GPU 之间的高效数据共享和通信至关重要。
直连结构 - 2 CPU,无 PCIe 交换机
在直连设置中,每个 CPU 可以直接通过 PCIe 访问服务器中最多四个 GPU,每个 GPU,合计 8 个 GPU,而无需使用 PLX 交换机。
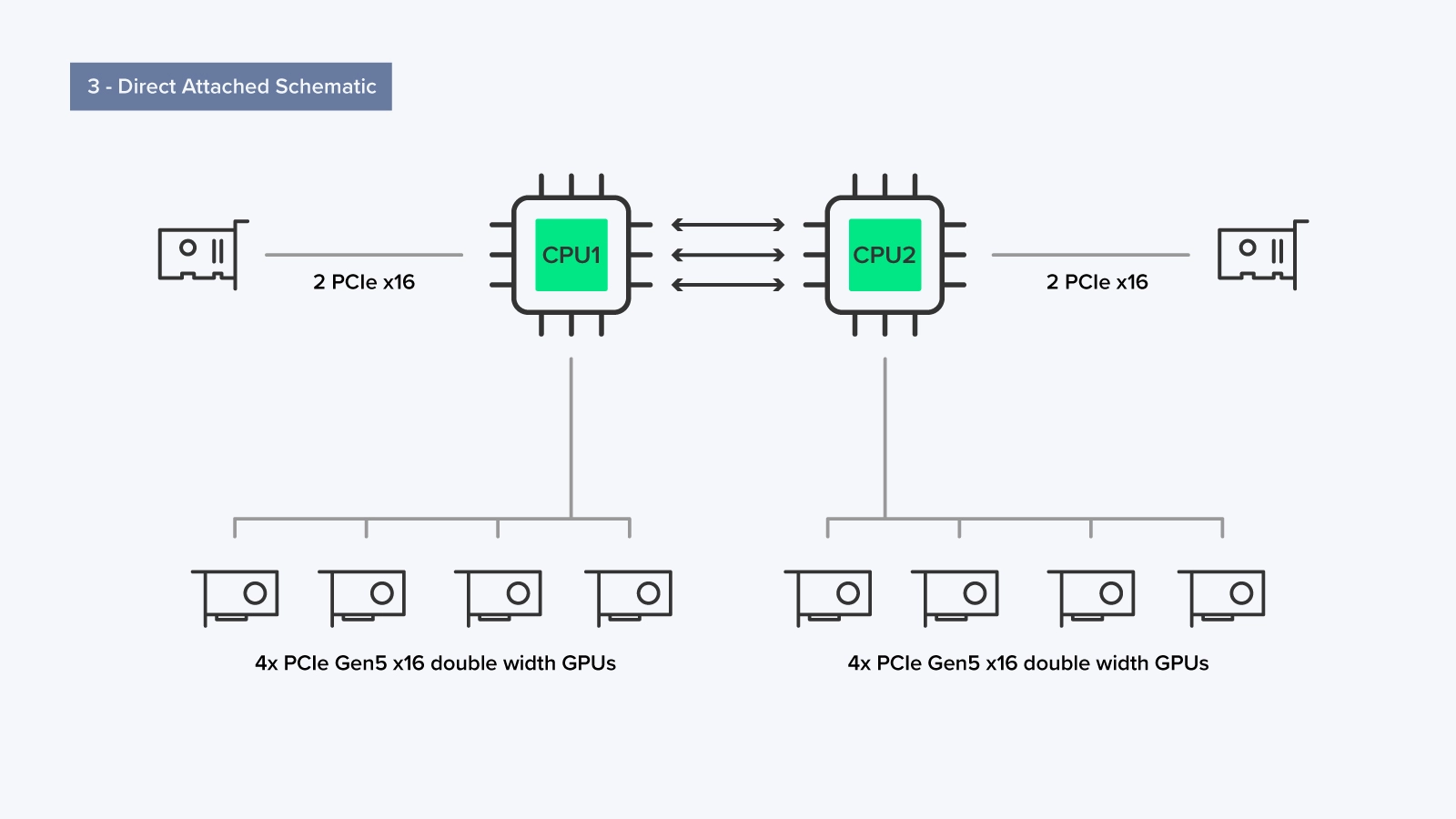
这种配置的优点在于没有 PLX 交换机。在 Single Root 和 Dual Root 中,PLX 交换机通过整合和重新分配 PCIe 设备的数据流量,充当主板上未直接跟踪的 PCIe 通道插槽的流量控制器。这减少了已使用的 PCIe 通道的数量,同时确保了最佳带宽以获得最佳性能。然而,这是一种权衡;使用 PLX 会增加数据通过它时的延迟,就像中间人一样。由于 GPU 与 CPU 的直接连接,直接连接设置中缺少 PLX 可减少延迟。
在像这样的 8 GPU 设置中,我们总共为 GPU 使用了 128 个 PCIe 5.0 通道。直接连接的设置通常用于大多数 HPC(高性能计算)工作负载,其中多个应用程序可以同时运行,或者单个应用程序可以划分为多个较小的作业。在这种设置中,每个 CPU 都有平等的访问权限,并且在 CPU 上运行的每个应用程序都可以专用地访问其自己的一组 GPU 资源,同时降低延迟和复杂性。
如何选择服务器
· Single Root
· 通用工作负载:Single Root GPU 服务器适用于广泛的通用 GPU 加速工作负载,如科学模拟、数据分析和机器学习训练,如您不需要高 GPU 到 GPU 的通信时。
· Web 服务器和虚拟化:这些服务器也可以用于 Web 托管和虚拟化任务,其中每个虚拟机(VM)或容器不需要直接的 GPU 通信。
· Dual Root
· 高性能计算(HPC):对于需要高 GPU 到 GPU 通信的 HPC 工作负载,如涉及复杂模型或大规模科学计算的模拟,通常首选 Dual Root GPU 服务器。
· 深度学习和人工智能训练:在多个 GPU 上训练深度学习模型时,Dual Root 服务器可以通过实现 GPU 之间更快的数据交换来提供更好的性能。
· 直连
· 图形渲染和视频编辑:直连 GPU 服务器非常适合图形密集型应用程序,如 3D 渲染、视频编辑和计算机辅助设计(CAD)。这些任务受益于直接 GPU 访问,而不需要 GPU 间通信。
· 远程桌面虚拟化:直连 GPU 可用于远程桌面虚拟场景,其中每个用户或会话都需要专用 GPU 资源来执行游戏或图形设计等任务。
探索更多联泰集群 4U 服务器,该系列服务器具有来自 Intel 和 AMD 的大量平台可供选择。与我们的工程师一对一沟通,获得有关如何配置解决方案的定制化建议!



相关贴子
-
 HPC
HPC集群拓扑结构:什么是头节点?
2023.01.12 31分钟阅读 -
 HPC
HPCGTC22 | 探索人工智能(AI)赋能的交通运输业新前沿
2022.07.14 0分钟阅读 -
 HPC
HPCGPU 加速度驱动的计算流体力学革命
2022.07.14 102分钟阅读