
博客
大语言模型如何突破百万 Token 上下文窗口?—— 解析上下文并行与环形注意力技术

引言:上下文长度与硬件扩展性的博弈
Introduction: Context Length and Hardware Scalability 01
短短几年内,大语言模型(LLM)的上下文窗口已实现爆发式增长 —— 从最初的 4k Token 跃升至千万级。Meta 的 Llama 4 Scout 支持 1000 万 Token,是 Llama 3(128k Token)的 78 倍;Google 的 Gemini 3 Pro 可处理 100 万 Token,Claude 4 也在测试版中支持 100 万 Token 上下文。
这一突破意味着模型可单次处理完整代码库、数百篇研究论文或数日时长的对话历史。但核心问题随之而来:上下文长度的增长速度已远超硬件承载能力。
以 32 位精度训练一个 4050 亿参数的模型,仅模型本身就需约 6.5TB 内存;再叠加梯度、优化器状态以及随上下文长度呈二次方增长的激活值,即便是单台配备 2.3TB HBM3e 内存的 B300 服务器也难以支撑。
关键数据换算:
- 模型参数:每 10 亿参数约占用 2GB 内存
- 梯度数据:与参数占用内存规模相当
- 优化器状态:参数内存规模的 2-3 倍
- 激活值:随上下文长度增长(注意力机制中呈二次方增长)
这迫使训练过程需跨数十甚至数百台 NVIDIA Blackwell GPU 进行多节点分布式部署,也正因如此,数据中心内的 NVIDIA NVLink(带宽 1.8TB/s)和 InfiniBand 成为不可或缺的核心网络技术。而真正的挑战并非简单拆分工作负载,而是 GPU 间拆分后产生的通信瓶颈。
并行计算基础原理
Parallelism Fundamentals 02
当模型或数据集规模超出单 GPU 承载能力时,并行计算策略通过拆分工作负载实现扩展,每种方案均以通信开销换取内存压力缓解:
数据并行:
完整模型加载至每台 GPU,训练数据拆分到不同设备,各 GPU 处理不同批次数据,每步训练后同步梯度。适用于模型较小、计算为瓶颈而非内存的场景。
- 模型并行:当模型规模超出单 GPU 承载时,将模型拆分到多台 GPU,不同层在不同 GPU 上顺序运行。对 4050 亿参数等超大规模架构至关重要,但会产生 “流水线气泡”—— 部分 GPU 需等待上游层计算完成而闲置。
- 张量并行:当单个运算(如矩阵乘法)也无法在单 GPU 上完成时,将运算按行或列拆分到多台设备,再通过全归约(all-reduce)操作合并结果。适用于模型层规模超出单 GPU 内存的超大规模训练场景。
- 局限性:当模型规模庞大且上下文窗口扩展至百万 Token 级时,即便张量并行也难以应对。注意力机制的二次方内存增长特性,导致激活值成为内存占用的主导因素 ——128k Token 上下文所需的激活值内存,是 8k Token 场景的 16 倍。
上下文并行 vs 序列并行
Context Parallelism vs Sequence Parallelism 03
序列并行与上下文并行均通过跨设备拆分序列解决内存约束,但应用范围与适用场景存在本质差异:
- 序列并行:与张量并行配合使用,仅将非矩阵乘法运算(如层归一化、dropout)按序列维度拆分,每台设备处理张量并行未覆盖运算的部分激活值。虽能扩展序列长度支持,但受限于注意力机制的二次方内存增长,在 128k Token 以上场景仍面临瓶颈。
- 上下文并行:将完整序列拆分到所有模块,而非仅针对非矩阵乘法运算 —— 包括注意力机制在内的所有操作均处理拆分后的序列片段。通过分散海量激活值的内存占用,实现百万 Token 级上下文的训练。
注意力机制的核心挑战
多数模型运算可独立处理单个 Token,并行化实现相对简单。但注意力机制截然不同:每个 Token 需与序列中所有其他 Token 进行关联计算。当序列拆分到多台 GPU 后,如何让 GPU 1 上的 Token 与 GPU 2 上的 Token 进行注意力交互,且不导致整体计算停滞?
这正是环形注意力(Ring Attention)技术的核心价值 —— 支持数据中心内多节点、多 GPU 的 LLM 训练与推理。
之字形环形注意力:计算与通信的重叠优化
Zig Zag Ring Attention: Overlapping Communication and Computation 04
环形注意力通过将 GPU 组织成环形拓扑,解决跨设备注意力计算问题,具体流程如下:
- 每台 GPU 存储序列的查询(Q)、键(K)、值(V)张量片段;
- 利用本地 K、V 张量计算自身 Q 片段的注意力;
- 将本地 K、V 张量传递给环形拓扑中的下一台 GPU;
- 接收环形拓扑中前一台 GPU 传递的 K、V 张量;
重复上述步骤,直至所有 Q Token 完成与所有 K/V Token 的注意力计算。
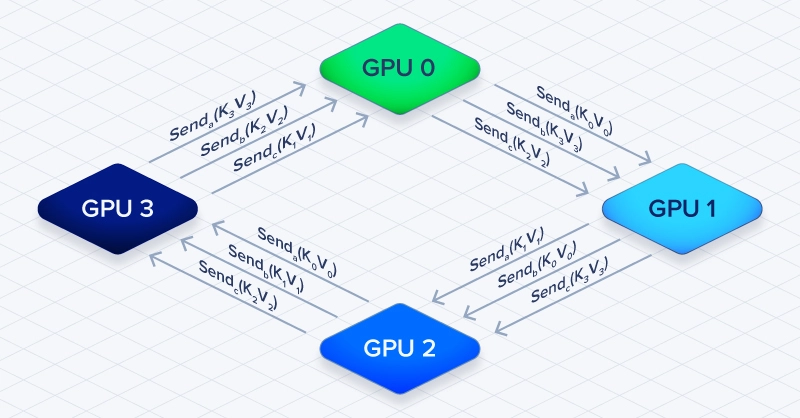
环形注意力的核心优势
实现计算与通信的重叠:当 GPU 1 利用当前 K/V 片段进行注意力计算时,可同步接收来自 GPU 0 的下一批 K/V 片段。这种设计将通信延迟隐藏在计算过程中,避免了 GPU 等待完整序列数据再启动计算的停滞问题。
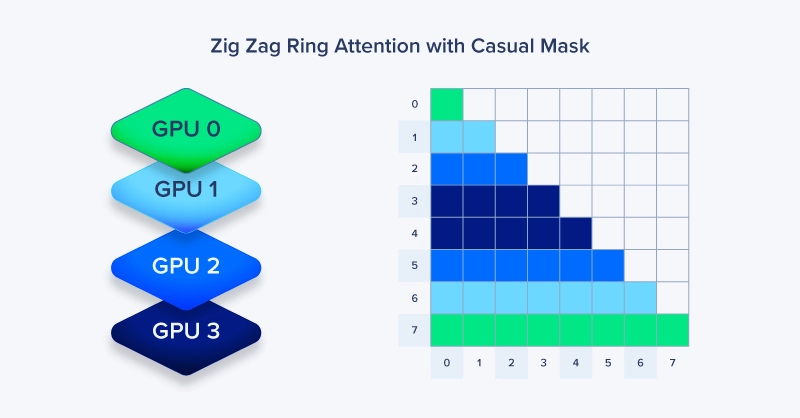
在 GPT 等自回归模型中,Token 仅需关注前文 Token 而非后续 Token,这会导致负载不均衡 —— 部分 GPU 出现闲置。之字形环形注意力通过 “交错式” 序列拆分替代 “顺序式” 块拆分,解决了这一问题:GPU 0 处理 Token [0, 4, 8...],GPU 1 处理 [1, 5, 9...],以此类推。这种方式确保每台 GPU 均能均衡分配早期与晚期 Token,在因果注意力计算中实现 GPU 负载均衡,避免环形拓扑中的设备闲置。
该设计在保持环形通信结构的同时,即便在因果掩码场景下也能实现近乎完美的 GPU 利用率。其代价是索引逻辑略为复杂,但在大规模训练场景下的性能收益极为显著。
上下文并行与环形注意力常见问题解答
FAQ for Context Parallelism and Ring Attention 05
- Transformer 模型中的上下文并行是什么?
上下文并行通过将输入序列拆分到多台 GPU,解决训练过程中的内存约束。与张量并行或数据并行不同,它将序列维度拆分到所有模型模块,支持训练超出单 GPU 内存容量的百万 Token 级上下文。
2. 环形注意力如何缓解 GPU 内存瓶颈?
环形注意力将 GPU 组织成环形拓扑,每台设备在利用已有数据进行注意力计算的同时,向下一台设备传递键值对。这种计算与通信的重叠设计,使全对全(all-to-all)注意力计算无需等待完整序列数据,避免了 GPU 停滞。
3. 序列并行与上下文并行的核心区别是什么?
序列并行仅拆分非矩阵乘法运算(如层归一化),需与张量并行配合使用;上下文并行则将完整序列拆分到所有模块(包括注意力机制),是处理 128k Token 以上上下文场景的必需方案 —— 此类场景中激活值内存呈二次方增长。
4. 之字形环形注意力为何优于标准环形注意力?
之字形环形注意力采用交错式序列拆分而非顺序分配,在因果掩码场景下实现 GPU 负载均衡。标准环形注意力可能导致后期 GPU 等待早期片段,而之字形设计将早期与晚期 Token 均匀分布到所有设备,避免闲置。
5. 训练百万 Token 上下文模型需要哪些硬件支持?
训练百万 Token 上下文模型需搭建多节点 GPU 集群:GPU 需配备高带宽内存(HBM),并搭配 NVIDIA NVLink(1.8TB/s)或 InfiniBand 等高速互联技术。对于 4050 亿参数模型的 32 位精度从头训练与推理,机架式部署 4 台 NVIDIA HGX B300 服务器是理想的起步配置。
核心结论:在不突破硬件限制的前提下扩展上下文长度
Key Takeaways: Scaling Context Without Breaking Hardware 06
上下文并行以通信开销换取内存压力缓解,但这一权衡仅在硬件性能跟进时成立。网络带宽是关键瓶颈:环形注意力需要 GPU 间持续交换键值对,若数据传输时间超过计算时间,设备将重回等待状态而非持续计算。
关键资源推荐
- Hugging Face Accelerate:上下文并行官方指南
- 环形注意力(原始论文)
- 最新上下文并行研究成果
在多机架部署场景中,配备 NVIDIA NVLink(1.8TB/s)和 InfiniBand 的高速互联技术至关重要。互联带宽必须与 GPU 计算吞吐量匹配,否则上下文并行的有效性将大幅下降。
若您计划设计下一代多节点机架式集群,联泰集群提供一站式解决方案 —— 可灵活配置 GPU 计算单元、存储系统与管理模块。我们的团队将评估您的预算、部署环境等关键因素,助力您快速落地集群建设并投入使用。





相关贴子
-
 技术分享
技术分享使用 cuCIM 和 NVIDIA GPU DIRECT STORAGE加速数字病理学工作流程
2023.01.12 86分钟阅读 -
 技术分享
技术分享【技术大讲堂】Perturbo-2.0 的安装
2024.09.13 29分钟阅读 -
 技术分享
技术分享基于 NVIDIA DGX Spark 本地智能体 AI 基准评测(Ollama+OpenClaw 方案)
2026.06.12 109分钟阅读