
博客
检索增强生成如何使 LLM 比以前更智能
01 理想生成型人工智能与现实
基础 LLM 已经阅读了他们能找到的每一个字节的文本,他们的聊天机器人对手可以被提示进行智能对话,并被要求执行特定的任务。全面信息的获取已实现民主化;不再需要找出正确的关键字进行搜索或选择要阅读的网站。然而,LLM 倾向于散漫,通常会以你希望听到的统计上最可能的反应(阿谀奉承)来回应变压器模型的固有结果。从法学硕士的知识库中提取100%准确的信息并不总是能产生值得信赖的结果。
Chat LLMs 因引用不存在的科学论文或法庭案件而臭名昭著。对一家航空公司提起诉讼的律师引用了从未实际发生过的法庭案件。2023年的一项研究报告称,当 ChatGPT 被提示包含引用时,它只提供了14%的参考文献。伪造来源、漫无边际、提供不准确信息以安抚提示被称为幻觉,在人工智能被大众完全采用和信任之前,这是一个需要克服的巨大障碍。
对抗 LLM 编造虚假来源或提出不准确信息的一个方法是检索增强生成或 RAG。RAG 不仅可以降低 LLM 产生幻觉的倾向,还具有其他几个优点。
这些优势包括访问更新的知识库、专业化(例如通过提供私人数据源)、为模型提供超出参数存储器存储的信息(允许更小的模型),以及从合法参考中获取更多数据的潜力。
02 什么是 RAG(检索增强生成)?
检索增强生成(RAG)是一种在 LLM 和变压器网络中实现的深度学习架构,它检索相关文档或其他片段,并将其添加到上下文窗口中以提供额外信息,帮助 LLM 生成有用的响应。典型的 RAG 系统有两个主要模块:检索和生成。
检索增强生成架构
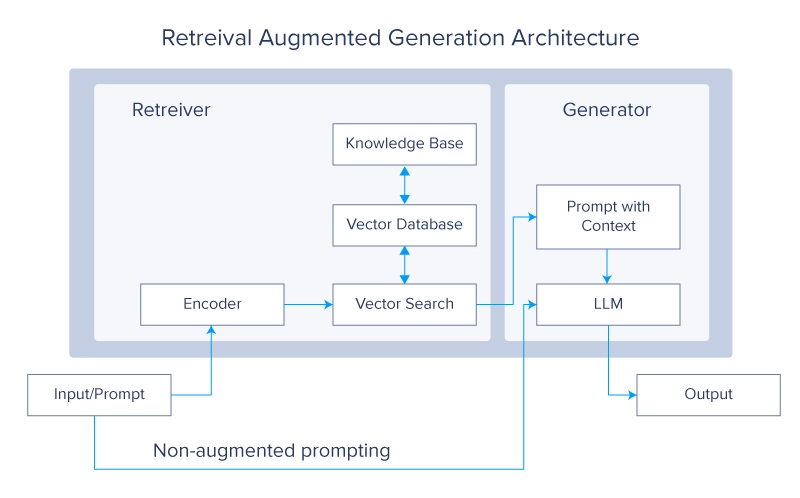
RAG 的主要参考文献是 Lewis 等人在脸书上发表的一篇论文。在这篇论文中,作者使用了一对基于 BERT 的文档编码器,通过将文本嵌入矢量格式来转换查询和文档。然后,这些嵌入用于通过最大内积搜索(MIPS)识别前k个(通常为5或10个)文档。顾名思义,MIPS 基于查询的编码向量表示与向量数据库中为用作外部非参数存储器的文档预先计算的向量表示的内积(或点积)。
正如 Lewis 等人在文章中所述,RAG 旨在使 LLM 更好地完成知识密集型任务,这些任务“在没有外部知识源的情况下,人类无法合理地执行”。考虑参加开卷和非开卷考试,你会很好地了解 RAG 如何补充基于 LLM 的系统。
03 使用 Hugging Face 库的 RAG 模型
Lewis 等人在 Hugging Face Hub 上开源了他们的 RAG 模型,因此我们可以使用本文中使用的相同模型进行实验。建议使用带有 virtualenv 的新 Python 3.8虚拟环境。
virtualenv my_env --python=python3.8 source my_env/bin/activate
激活环境后,我们可以使用 pip 安装依赖关系:Hugging Face 的变压器和数据集,RAG 用于矢量搜索的 Facebook FAISS 库,以及用作后端的 PyTorch。
pip install transformers pip install datasets pip install faiss-cpu==1.8.0 #https://pytorch.org/get-started/locally/ to #match the pytorch version to your system pip install torch
Lewis 等人实现了 RAG 的两个不同版本:RAG 序列和 RAG 令牌。Rag 序列使用相同的检索文档来增强整个序列的生成,而 Rag 令牌可以为每个令牌使用不同的片段。两个版本都使用相同的 Hugging Face 类进行标记化和检索,API 也非常相同,但每个版本都有一个唯一的类用于生成。这些类是从 transformers 库导入的。
from transformers import RagTokenizer, RagRetriever from transformers import RagTokenForGeneration from transformers import RagSequenceForGeneration
首次实例化具有默认“wiki_dpr”数据集的 RagRetriever 模型时,它将启动大量下载(约300 GB)。如果你有一个大数据驱动器,并希望 Hugging Face 使用它(而不是你主驱动器中的默认缓存文件夹),你可以设置一个 shell 变量 HF_DATASETS_cache。
# in the shell: export HF_DATASETS_CACHE="/path/to/data/drive" # ^^ add to your ~/.bashrc file if you want to set the variable
在下载完整的 wiki_dpr 数据集之前,确保代码正常工作。为了在准备好之前避免大量下载,您可以在实例化检索器时传递 use_dummy_dataset=True。您还将实例化一个标记器,将字符串转换为整数索引(对应于词汇表中的标记),反之亦然。RAG 的序列和令牌版本使用相同的令牌化器。RAG 序列(rag-sequence)和 RAG 令牌(例如,rag-token)均具有微调版本(例如,rag-token-nq)和基础版本(例如,rag-token-base)。
tokenizer = RagTokenizer.from_pretrained(\ "facebook/rag-token-nq") token_retriever = RagRetriever.from_pretrained(\ "facebook/rag-token-nq", \ index_name="compressed", \ use_dummy_dataset=False) sequence_retriever = RagRetriever.from_pretrained(\ "facebook/rag-sequence-nq", \ index_name="compressed", \ use_dummy_dataset=False) dummy_retriever = RagRetriever.from_pretrained(\ "facebook/rag-sequence-nq", \ index_name="exact", \ use_dummy_dataset=True) token_model = RagTokenForGeneration.from_pretrained(\ "facebook/rag-token-nq", \ retriever=token_retriever) seq_model = RagTokenForGeneration.from_pretrained(\ "facebook/rag-sequence-nq", \ retriever=seq_retriever) dummy_model = RagTokenForGeneration.from_pretrained(\ "facebook/rag-sequence-nq", \ retriever=dummy_retriever)
一旦你的模型被实例化,你就可以提供一个查询,对其进行标记,并将其传递给模型的“生成”函数。我们将使用检索器将 rag-sequence、rag-token 和 Rag 的结果与 wiki_dpr 数据集的虚拟版本进行比较。请注意,这些抹布型号不区分大小写。
query = "what is the name of the oldest tree on Earth?" input_dict = tokenizer.prepare_seq2seq_batch(\ query, return_tensors="pt") token_generated = token_model.generate(**input_dict) token_decoded = token_tokenizer.batch_decode(\ token_generated, skip_special_tokens=True) seq_generated = seq_model.generate(**input_dict) seq_decoded = seq_tokenizer.batch_decode(\ seq_generated, skip_special_tokens=True) dummy_generated = dummy_model.generate(**input_dict) dummy_decoded = seq_tokenizer.batch_decode(\ dummy_generated, skip_special_tokens=True) print(f"answers to query '{query}': ") print(f"\t rag-sequence-nq: {seq_decoded[0]},"\ f" rag-token-nq: {token_decoded[0]},"\ f" rag (dummy): {dummy_decoded[0]}")
>>对“地球上最古老的树叫什么名字?”的回答:普罗米修斯是2012年之前发现的最古老的树,其最里面的现存年轮超过4862年。
>>rag-sequence-nq: prometheus, rag-token-nq: prometheus, rag (dummy): 4862
一般来说,rag-token 比 rag-sequence 更正确(尽管两者通常都是正确的),并且 rag-sequence 比使用具有虚拟数据集的检索器的 Rag 更正确。
“检索器提供了什么样的上下文?”你可能会想知道。为了找到答案,我们可以解构生成过程。使用如上所述实例化的 seq_retriever 和 seq_model,我们查询“地球上最古老的树的名字是什么”
query = "what is the name of the oldest tree on Earth?" inputs = tokenizer(query, return_tensors="pt") input_ids = inputs["input_ids"] question_hidden_states = seq_model.question_encoder(input_ids)[0] docs_dict = seq_retriever(input_ids.numpy(),\ question_hidden_states.detach().numpy(),\ return_tensors="pt") doc_scores = torch.bmm(\ question_hidden_states.unsqueeze(1),\ docs_dict["retrieved_doc_embeds"]\ .float().transpose(1, 2)).squeeze(1) generated = model.generate(\ context_input_ids=docs_dict["context_input_ids"],\ context_attention_mask=\ docs_dict["context_attention_mask"],\ doc_scores=doc_scores) generated_string = tokenizer.batch_decode(\ generated,\ skip_special_tokens=True) contexts = tokenizer.batch_decode(\ docs_dict["context_input_ids"],\ attention_mask=docs_dict["context_attention_mask"],\ skip_special_tokens=True) best_context = contexts[doc_scores.argmax()]
我们可以对模型进行编码,打印变量“最佳上下文”,以查看捕获的内容
print(f" based on the retrieved context"\ f":\n\n\t {best_context}: \n")
基于检索到的上下文:
普罗米修斯(树)/然而,在克隆生物中,单个克隆茎并没有那么老,在任何时候,生物的任何部分都没有特别老。直到2012年,普罗米修斯是迄今为止发现的最古老的“非克隆”生物,其最内层的现存环的年龄超过4862岁。20世纪50年代,树木年代学专家正在积极努力寻找最古老的现存树种,以便将年轮分析用于各种研究目的,如评估以前的气候、考古遗址的年代,以及解决最大潜在寿命的基本科学问题。狐尾松//地球上最古老的树叫什么名字?
print(f" rag-sequence-nq answers '{query}'"\ f" with '{generated_string[0]}'")
我们还可以通过调用“generated_string”变量来打印答案。让 rag-sequence-nq 回答“地球上最古老的树叫什么名字?”“普罗米修斯”。
04 你能用 RAG 做什么?
在过去的一年半里,LLM 和 LLM 工具出现了名副其实的爆炸式增长。Lewis 等人使用的 BART 基础模型只有4亿个参数,与目前的 LLM 相去甚远,LLM 通常从“lite”变体的十亿个参数范围开始。此外,目前正在训练、合并和微调的许多模型都是多模态的,将文本输入和输出与图像或其他标记化数据源相结合。将 RAG 与其他工具结合可以构建复杂的功能,但底层模型也无法避免常见的 LLM 缺点。LLM 中的阿谀奉承、幻觉和可靠性问题仍然存在,并且随着 LLM 使用的增长,这些问题也有增长的风险。
RAG 最明显的应用是会话语义搜索的变体,但也许它们还包括将多模态输入或图像生成作为输出的一部分。例如,具有领域知识的 LLM 中的 RAG 可以制作您可以聊天的软件文档。或者,RAG 可用于在研究项目或论文的文献综述中保留交互式笔记。
结合“思维链”推理能力,您可以采取更具代理性的方法,使您的模型能够查询 RAG 系统,并组装更复杂的查询或推理线路。
同样重要的是要记住,RAG 并不能解决常见的 LLM 陷阱(幻觉、阿谀奉承等),而只能作为缓解或引导 LLM 做出更小众反应的一种手段。最终重要的端点特定于您的用例、您为模型提供的信息以及模型的微调方式。





相关贴子
-
 人工智能与大模型
人工智能与大模型AlphaFold 3-扩散彻底改变了分子结构预测
2024.08.09 22分钟阅读 -
 人工智能与大模型
人工智能与大模型什么是多层感知以及何时使用 MLP 与 Transformers
2025.06.20 48分钟阅读 -
 人工智能与大模型
人工智能与大模型SR223 V2 服务器 - 推动企业技术革新的关键力量
2024.09.06 33分钟阅读