
博客
GPU 加速度驱动的计算流体力学革命
By Chris Porter and Niveditha Krishnamoorthy
转自英伟达开发者论坛
当一项技术达到所需的成熟度时,采用将从那些被认为是有远见的人转变为早期的多数采用者。现在是工业 high-performance computing ( HPC )最大单一细分市场的关键和过渡时刻。
2021 年底和 2022 年初,两家最大的商业计算流体动力学( CFD )工具供应商 Ansys 和西门子都推出了其旗舰 CFD 工具版本,支持 GPU 加速。仅这一事实就足以证明 CFD 的新时代已经到来。
CFD 工程应用的发展
过去十年, CFD 被广泛采用,作为工程师和设备设计师研究或预测其设计行为的关键工具。然而, CFD 不仅仅是一种分析工具,它现在被用来进行设计改进,而无需对每个正在评估的设计/操作点进行耗时且昂贵的物理测试。这种普遍性是为什么今天有这么多 CFD 工具、商业和开源软件可用的部分原因。
对模拟精度的日益增长的需求有助于将测试最小化,这导致了 将多种物理功能纳入 CFD 工具 ,例如包括传热、传质、化学反应、颗粒流等。 CFD 工具增长的另一个原因是,在一个工具中捕获每种类型用例的所有相关物理数据是一项耗时的工作。
例如,在车辆空气动力学的使用案例中,数字风洞可用于研究和评估几何体上的气流,并评估设计表面产生的阻力,这对车辆性能有直接影响。根据模拟的预期目的,用户可以选择是否使用传统的流体流动 Navier-Stokes 公式或使用 替代框架,如晶格玻耳兹曼方法 进行稳态或瞬态模拟。
即使在 Navier-Stokes 解决方案的领域内,也有各种湍流模型和方法,如分辨率和建模的尺度,可供选择用于模拟。在进行设计选择时,如果考虑到其他物理因素,例如研究对客户感知、乘客安全和舒适性有影响的汽车气动声学,或研究道路车辆排列,模型的复杂性会迅速增加。
所有用于建模不同流动情况的工具都需要惊人的计算处理能力。随着各组织开始在其设计周期的早期将 CFD 纳入其中,同时在模型尺寸和代表性物理方面增加其模型的复杂性,以提高模拟的保真度,该行业已经达到了一个转折点。
并行性等同于性能
单个模拟需要数千个 CPU 核心小时才能提供结果的情况已不再少见,单个设计产品可能需要10000到1000000个模拟或更多。
就在最近, NVIDIA 的一家合作伙伴 Resolved Analytics 发布了一份 CFD 用户和工具调查。 统计数据,其中显示了 CFD 用户目前常用的并行度。在 CFD 中,并行执行是指将域或网格划分为子网格,并为每个子网格分配一个处理单元。在每次数值迭代中,子网格与相邻子网格传递边界信息, CFD 解趋于收敛。
调查结束时得出的结论是,硬件和软件成本继续限制 CFD 的并行化。
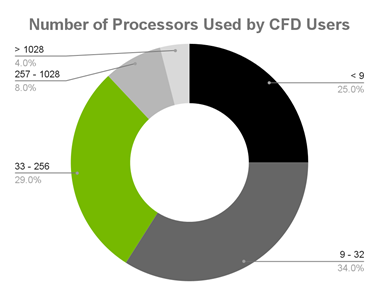
图1:Resolved Analytics survey of CFD users
Resolved Analytics 调查了 CFD 用户,发现绝大多数用户使用的处理器少于 257 个,影响了并行编程能力:
> 25% 的 CFD 用户使用的处理器少于 9 个。
> 34% 的用户使用 9-32 个处理器。
> 29% 使用 33-256 个处理器。
> 8% 使用 257-1028 处理器。
> 4% 使用超过 1028 个处理器。
另一种思考方法是 并行性等同于性能,运行时等同于最小化 。这意味着,如果您不受硬件和软件许可证的限制,您可以将性能提升到今天的水平。
获得更高级别的性能是正确的,因为它优化了最昂贵的资源:工程师和研究人员的时间。通常,熟练人员的时间可能是第二昂贵资源(软件许可证或计算硬件)成本的 5-10 倍。逻辑要求分配资金,以消除这些低成本资源造成的瓶颈。
另一个 NVIDIA 合作伙伴 Rescale 以类似的方式陈述了 perspective :
大多数 HPC 经济模型忽略了工程时间或工程生产率,而这是最有价值和最昂贵的资源,需要首先进行优化。确保硬件和软件资产使研究人员能够以最大速度生成知识产权,这是对待组织核心价值生成器的最合理方式。
NVIDIA 很高兴与CFD用户社区分享硬件限制正在解除。最近,西门子数字工业软件公司(Siemens Digital Industries Software)和Ansys Fluent提供的两种最流行的CFD工具Simcenter STAR-CCM+已经提供了软件版本,以帮助支持特定的物理。这些物理模拟可以充分利用加速计算的极端速度。
在发布本文时, Simcenter STAR-CCM + 2022.1 GPU 加速版已普遍可用,目前支持车辆外部空气动力学应用程序进行稳态和非稳态模拟。 Ansys Fluent 版本目前正在公测中。
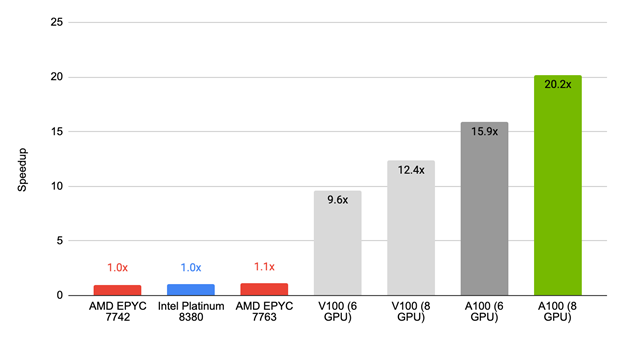
图 2 :Simcenter STAR-CCM + 2022.1 在 GPU 上的 LeMans 104M 型性能与仅 CPU 执行相比显示,性能最好的平台是 NVIDIA A100 PCIe 80GB ,速度高 20 倍。
图 2 显示了 Simcenter STAR-CCM + 2022.1 的第一个版本相对于常见的仅 CPU 服务器的性能。对于经过测试的基准测试,配备 NVIDIA GPU 的服务器提供的结果比 100 多核 CPU 快近 20 倍。
AMD EPYC 7763 的加速比为 1.1 倍,相比之下, NVIDIA V100 (六个 GPU )的加速比为 9.6 倍, NVIDIA V100 (八个 GPU )的加速比为 12.4 倍, NVIDIA A100 (六个 GPU )的加速比为 15.9 倍, NVIDIA A100 (八个 GPU )的加速比为 20.2 倍。
从更实际的角度来看,这意味着在一台 CPU 服务器上进行一整天的模拟只需一个多小时,就可以用一个节点和八个 NVIDIA A100 GPU 完成。
随着 Simcenter STAR-CCM +团队继续致力于改进和优化其 GPU 产品,您可以期望在即将发布的版本中获得更好的性能。

图 3 :Simcenter STAR-CCM +压力系数平均值的结果比较于 (left) GPU- 和 (right) CPU-based runs.
Corvette C6 ZR1 外部空气动力学,伪稳态模拟, 110M 单元使用 SST-DDES 和车轮移动参考框架( MRF )运行。 GPU 在 4xA100 DGX 站上运行。
与仅使用 CPU 的运行相比, GPU 加速运行可提供一致的结果,西门子提供的产品可以无缝地从 CPU 移动到 GPU ,以更快、更轻松地获得结果。结果是,您现在可以在本地或云上运行模拟,因为所有主要云服务提供商都提供了 100 个 GPU 实例。
西门子在其 2022.1 版中宣布支持 GPU 比较上一代 V100 GPU 和当前一代 A100 GPU 的本地和云中仅 CPU 的服务器时。他们还展示了一个大型工业模型的性能,以及获得与具有八个 GPU 的单个节点相似的运行时间所需的 CPU 核的等效数量。
NVIDIA 和 Ansys 宣布 在 2021 GTC 秋季主题演讲上, GPU 加速、功能有限 Fluent 的公测可用性。
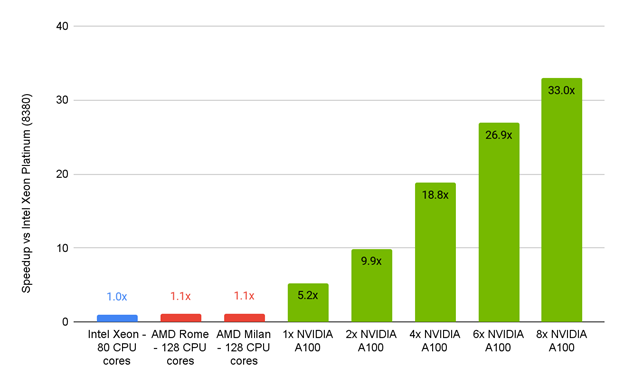
图 4 :105M 单元汽车模型服务器与仅 CPU 服务器的 Ansys FLUENT 2022 beta1 性能对比。
该比较基于 100 次迭代定时稳态 GEKO 湍流模型 .
与纯 CPU 服务器相比, Ansys Fluent 2022 beta1 服务器的性能表明, Intel Xeon 、 AMD Rome 和 AMD Milan 的加速比为 1.1 倍左右,而 NVIDIA A100 PCIe 80GB 的加速比为 5.2 倍(一个 GPU )到令人印象深刻的 33 倍(八个 GPU )。
Ansys 流畅的数字让人兴奋不已。他们表明,为他们选定的基准测试和相关物理性能设计的一台 GPU 加速服务器,其性能可以达到目前常见的标准纯英特尔处理器服务器的近 33 倍。
如此快速的周转时间是由于两个最常用的商业CFD应用程序的加速。这意味着设计工程师不仅可以在设计周期的早期将仿真纳入其中,还可以在一天内探索多个设计迭代。他们可以快速做出关于产品性能的明智决策,而无需等待数周。
GPU 加速的其他选项
以这样的速度,产品研究过程中可能会出现其他瓶颈。有时,工程时间的主要消耗是预处理,或手动构建要运行的模型的过程。
解决这个问题尤其重要,因为它需要工程人员的时间来解决。这与其他因素不同,比如模拟运行时间,它让研究人员可以自由地专注于其他任务。这是最近在 CFD 网格生成器:影响分析速度的三大原因及解决方法 中强调的一个活跃的焦点领域。
尽管如此,加速度并不是一个全新的现象。更多的工具要么诞生于GPU加速的世界,要么很快就会出现:
> Altair CFD 、 nanoFluidX 、 ultraFluidX 和 Acusolve
> Cascade Technologies , CharLES
> BarraCUDA
> 达索系统, Simulia XFlow
> 数字系统, pacefish
> Prometec , Particleworks
> M-Star CFD
> NASA , FUN3D
NVIDIA 展示了 NASA 的 FUN3D 工具 令人兴奋和视觉震撼的结果,包括黄仁勋分享火星着陆器进入大气层的模拟。
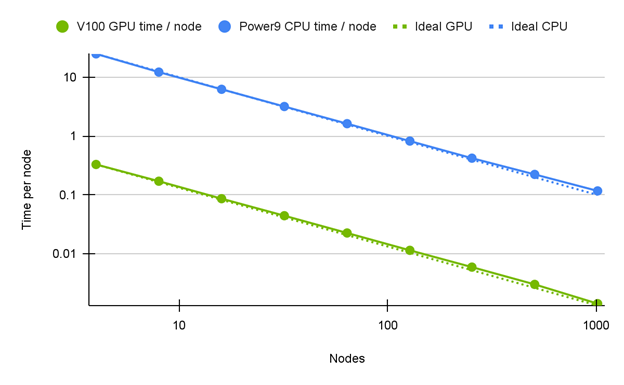
图 5 :由 NASA FUN3D 团队提供, CPU 与 GPU 相比, FUN3D 版本 14.0 (未发布)的性能提高了 72-84 倍。
ORNL Summit 使用 IBM AC922 Dual Power9 CPU 和 6x NVIDIA V100 SXM2 16 GB 2x EDR InfiniBand 提供硬件访问。
最近的超级计算会议的一个研究小组研究了大规模并行计算环境所需的VZX19。几个内核的运行时间主要取决于更新速度,因此在这一领域发现的效率可能带来巨大的好处。此外,尽管FUN3D是NASA和美国政府的专用工具,但本文的讨论也适用于其他非结构化雷诺平均Navier-Stokes CFD工具。
除了节省成本和消除障碍之外, GPU 加速的主流 CFD 工具最令人兴奋的部分可能是新的科学和工程技术,它将运行时间缩短了 15-30 倍。到目前为止,由于没有领导级超级计算能力,从运行时和问题规模的角度来看,对这些领域的调查都太困难了:
> 发动机罩下车辆建模:带传热的湍流
> 大涡流和燃烧:详细的环境排放建模需要
> 磁流体动力学:受磁场影响的流动对聚变能发生器、恒星内部和气体巨行星的建模非常重要
> 机器学习训练:自动生成用于训练机器学习算法的模型和解决方案,以估计流量初始条件、模型湍流、混合等
有关用于其他流体或工业模拟的加速计算的更多信息,请观看最近推荐的 GTC 2022 会议,重点讨论制造业和 HPC :
> 用 GPU 加速汽车噪声、振动和平顺性
> Accelerating high-fidelity 多物理流模拟
> 使用 NVIDIA DRIVE 加速自主车辆开发
> 解决车辆自主性方面的开放性研究挑战
> Fluent 中的非结构化多 GPU 隐式 CFD 求解器
> GP GPU 车辆外部空气动力学模拟的加速启用
关于作者

Chris 是 NVIDIA HPC 和 AI 的高级技术营销经理。此前,他在 IBM 担任聚合 HPC 和 AI 的产品经理,将 HPC 、 AI 和优化产品推向市场,专注于电子设计、航空航天和汽车行业。 Chris 拥有航空工程硕士学位,专注于设计优化。

Niveditha Krishnamoorthy 是 NVIDIA 的开发人员关系经理,专注于与计算机辅助工程( CAE )领域的独立软件供应商建立战略联盟。 15 年来,她一直应用计算流体力学研究湍流反应流系统的设计、放大和性能。她之前的工作经验包括 FM Global 的研发和西门子数字工业软件公司反应流技术专家。尼维迪莎拥有犹他大学化学工程博士学位。




相关贴子
-
 HPC
HPC低精度浮点数定义——什么是 FP8、FP6、FP4?
2026.01.16 47分钟阅读 -
 HPC
HPC工程仿真该选工作站还是服务器?
2025.08.22 37分钟阅读 -
 HPC
HPC集群拓扑结构:什么是头节点?
2024.01.12 42分钟阅读