
博客
技术分享
高效扩展 Polars 的 GPU Parquet 读取器
2025.04.11
29分钟阅读
高效扩展 Polars 的 GPU Parquet 读取器

规模因素和非分块读取器带来的挑战
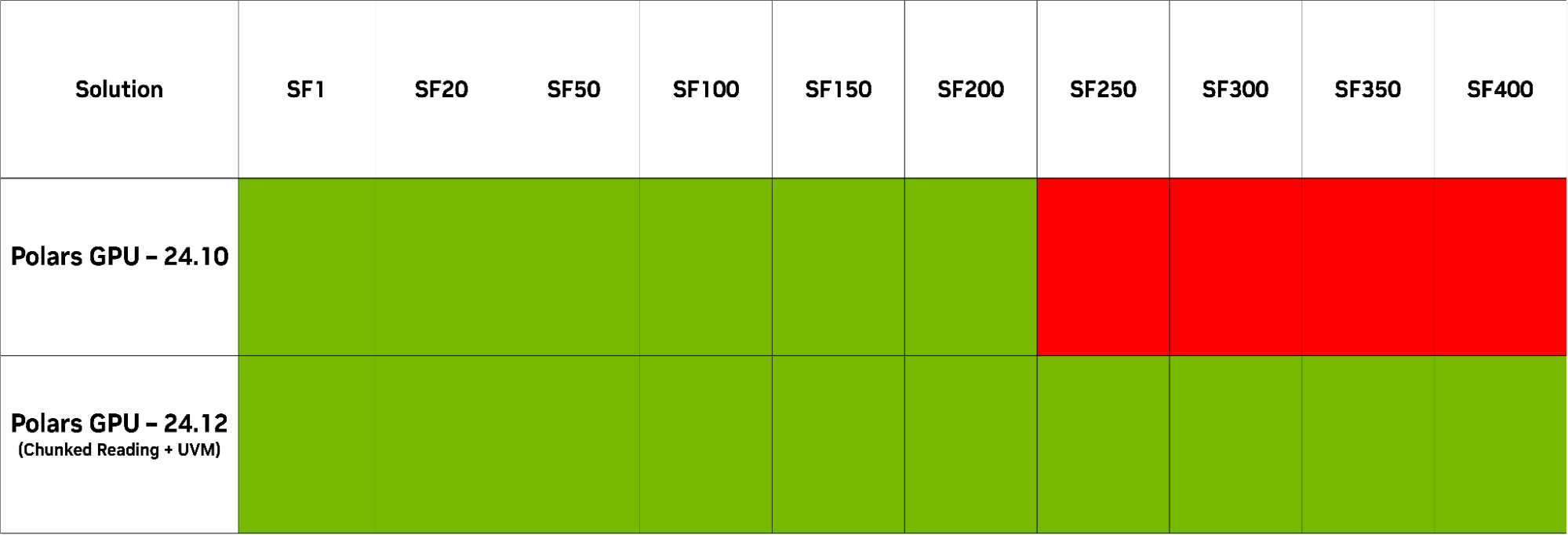
图 1.Query 13 执行可靠性,24.10 至 24.12 Parquet Reader 对比
通过分块 Parquet 读取改善 IO 和峰值内存
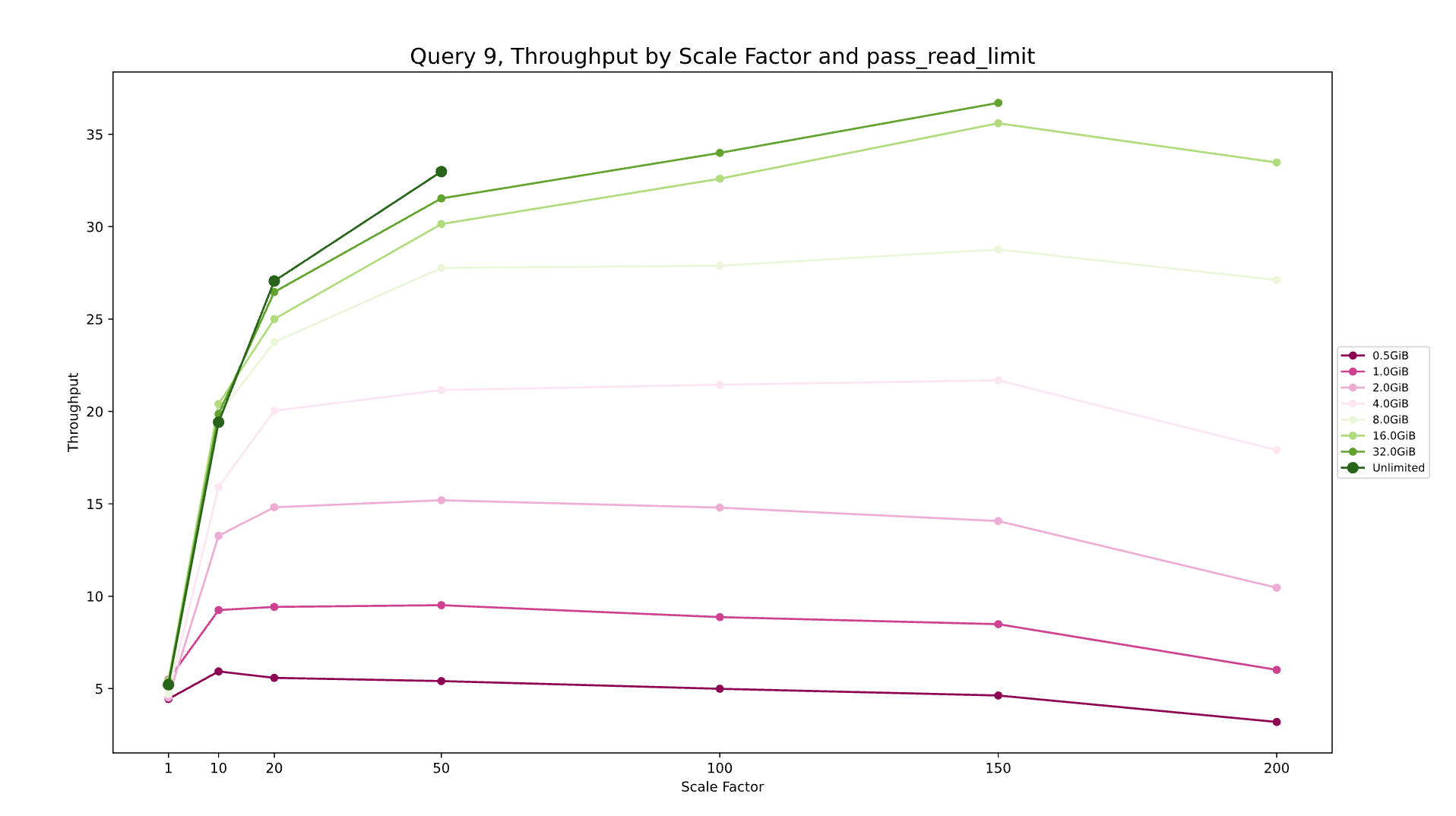
图 2.针对 Query 9 的不同规模因素按块大小 (pass_read_limit) 进行吞吐量比较
使用 UVM 读取更大的数据集
分块读取可改善内存管理,而 UVM 的集成可将性能提升至更高水平。UVM 使 GPU 能够直接访问系统内存,从而进一步缓解内存限制并提高数据传输效率。
为了进行比较,非 UVM 分块在达到 SF100 之前会遇到 OOM 错误。分块加 UVM 支持在更大规模的因素上成功执行查询,但吞吐量会受到影响。
图 3 显示了明显的优势。与非分块 Parquet Reader 相比,在启用 UVM 的分块 Parquet Reader 中成功执行的比例系数更多。
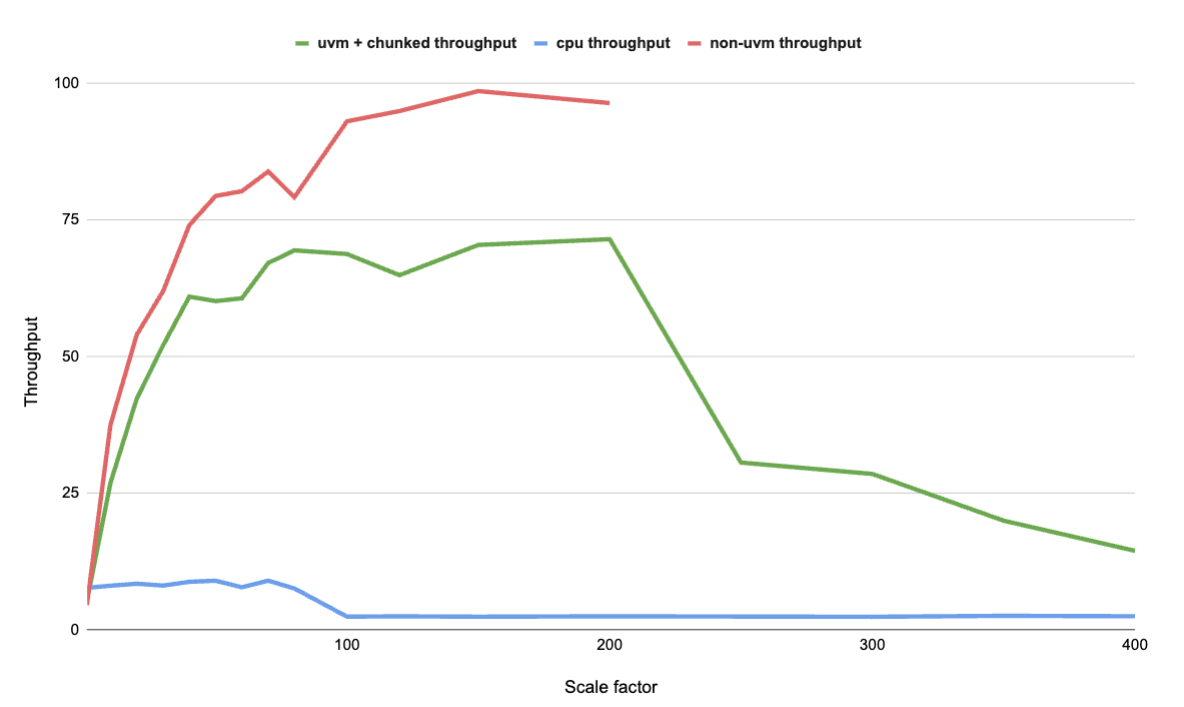
图 3.对于 Query 13,分块加 UVM 与 CPU 与非 UVM 的吞吐量比较 (越高越好)
稳定性与吞吐量
pass_read_limit 时,务必要考虑稳定性和吞吐量之间的平衡。图 1-3 表明,16 GB 或 32 GB pass_read_limit 是稳定性和吞吐量的最佳组合。-
32 GB
pass_read_limit:除 Query 9 和 Query 19 外,所有查询均已成功,但因 OOM 异常而失败 -
16 GB
pass_read_limit:所有查询均已成功
GPU 分块与 CPU 对比
pass_read_limit 似乎是合理的。与非分块 Parquet 相比,16 GB 或 32 GB pass_read_limit 可在更大规模的因子下成功执行。
总结
cudf-polars (24.12 及更高版本) 的一部分,分块的 Parquet Reader 和 UVM 是读取 Parquet 文件的默认方法。这使得上述所有查询和规模因素都得到了改进。




相关贴子
-
 技术分享
技术分享这台服务器正在悄悄改变中国 AI 产业格局!
2025.07.04 33分钟阅读 -
 技术分享
技术分享我们什么时候该对 LLM 进行微调和使用 RAG ?
2024.10.18 38分钟阅读 -
 技术分享
技术分享【技术大讲堂】ShengBTE 的安装与使用
2024.09.20 32分钟阅读