
博客
如何在非传统数据中心部署 GPU 服务器

并非所有工作负载都适合云端处理。从事人工智能推理、模拟或渲染的团队通常会更愿意从本地计算中受益。当数据集庞大、频繁或敏感时,在本地运行作业可以避免传输延迟、持续的云访问,并自由的控制自己的硬件。
GPU 服务器为这些任务提供了强大的加速能力,将其部署在本地,可降低持续的云成本。此外,它还消除了对共享基础设施的依赖,使团队能够在无使用限制或争用的情况下进行操作。
没错!事实上,许多企业并没有专门的数据中心来安置他们的服务器机架和 GPU 计算服务器。小型企业和实验室没有完整的数据中心;他们使用的是服务器机房、机柜和改造过的空间。只要部署计划周密,你就可以支持真正的 GPU 工作负载。
-
耗电量:GPU 服务器耗电量很大。在小型机架或机柜中,电源插座可能难以支撑。对于多 GPU 部署,考虑在机柜中安装三相电或单相电插座。
-
空间:空间是一个巨大的挑战,尤其是在那些并非专为机架部署而建造的房间中。对于狭小的机柜,需要仔细规划以进行电缆管理和服务接入。
-
散热:确保峰值性能需要高效的散热。如果通风受阻或供电不均,则会出现热降频或关机。解决方案包括使用空调系统和将热量排出机箱。

使用符合您的计算目标并在您的热预算和功耗预算范围内的 GPU 配置您的部署。
- 服务器外形:如果你的服务器机房或机柜空间有限,你仍然可以部署一个强大的 GPU 系统来为你的 HPC 工作负载供电。
-
如果房间很窄,可以考虑使用短深度机架式服务器
-
选择机架式工作站。虽然它们占用了更多的机架单元,但如果不是紧密地包装在一起,它们可能会有更好的通风条件,并且深度比标准服务器短
- GPU 选择:尽管旗舰级和顶级显卡备受瞩目,但低端 GPU 有时也可以满足您的空间和功耗需求,同时提供卓越的性能。
-
如果您的工作负载需要极高的性能,请继续使用 NVIDIA H 系列 NVL 和 RTX PRO 6000 Blackwell 等功能强大的显卡。为它们的高功耗和冷却要求做好准备。
-
对于分布式工作负载,低功耗卡可以提供更好的并行化。
-
如果服务器机房的通风有限,主动冷却 GPU 可以帮助散热,而被动冷却 GPU 则不然。
-
您不需要填充所有插槽。与最大限度地利用插槽相比,更少、高 VRAM 的 GPU 可以促进更好的散热。
- CPU 和内存:CPU 不应该成为 GPU 吞吐量的瓶颈。
-
使用具有高 PCI-e 通道数和足够内核的 CPU 来保持管道充足。
-
内存应与工作负载需求相匹配。人工智能训练和模拟可能需要 128GB 或更多。
- 存储和网络:快速的本地存储避免了 I/O 停滞。
-
尽可能通过 SATA 连接 NVMe SSD。
-
RAID 是可选的,但对弹性很有用。
-
用于共享工作负载的最低 10GbE 网络端口。
-
对于短距离和较少的开关,考虑直接连接电缆。
有了所有这些配置决策,做出正确的选择可能会变得混乱。联泰集群的工程团队将帮助您根据部署需求和配置限制来规划最佳解决方案。

供电规划
对于任何 HPC 服务器部署,您都需要稳定、高吞吐量的电源。配置服务器时使用联泰集群的 BTU 计算器,并留出 30% 的余量。
- 电路要求:GPU 服务器耗电严重,通常超过标准插座的安全供电能力。
-
首选带 20A 或 30A 断路器的高功耗电路
-
避免在共享的线路上运行高瓦数服务器
-
检查总功耗,而不仅仅是 GPU TDP——风扇、驱动器和 CPU 加起来
- 配电:使用具有清晰计量的 PDU。在线监测有助于在过载的分支跳闸之前发现它们,作为浪涌保护器,以防止停电
-
立式 PDU 节省机架空间。
-
水平单元在窄机架中工作得更好。
-
如果正常运行时间至关重要,请使用双转换 UPS 以增加冗余。
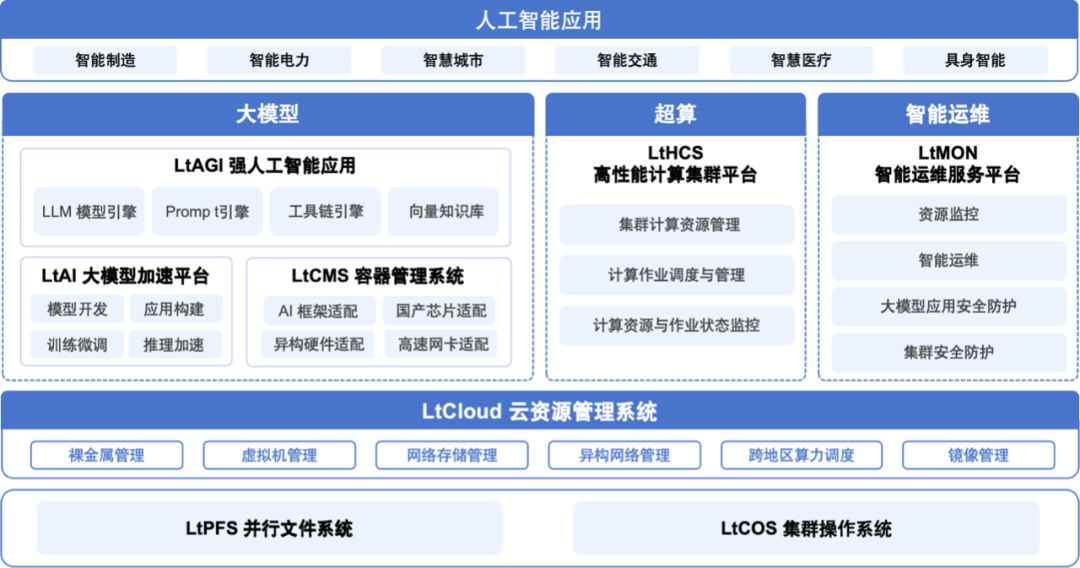
管理和监控电力和热力是数据中心 IT 的重要组成部分。利用 LtHCS 或 LtMON 等集群管理工具通过易用的 web 图形操作界面,高效的使用 HPC 计算集群中的各种计算资源。了解有关联泰集群的 LtAIDC 的更多信息,了解我们如何支持全面的机架集成,包括硬件、监控和电源管理。
冷却和通风
热量积聚得很快,尤其是在狭小的空间里。高性能 GPU 每个产生数百瓦的热负荷,当您将多个卡堆叠到机箱中时,气流路径变得至关重要。房间比服务器本身更重要。
- 气流原理:使用前后气流和热风上升原理的设备。
-
在服务器后面留出排气间隙
-
保持进气口清洁畅通
-
您可以使用底部为进气口、顶部为排气口的双通风门
- 机柜特定调整:机柜和改建的房间通常缺乏通风。
-
添加直列式风管风扇以抽出暖风
-
排气至天花板或相邻通风空间
-
如果房间是密封的,安装一个回风口
- 噪音、安全性和成本:大多数服务器都不安静,高电力会造成火灾隐患
-
服务器机房隔音板和阻燃衬里
-
通宵运行长工作负载,以应对持续的噪音并降低能源成本
在机柜里运行 GPU 已被证明是有效的,但并非没有计划。温度是硬件的敌人,会缩短使用寿命并增加碰撞风险。所以,冷却是部署 HPC 硬件的最重要因素。
Q:我可以在没有完整数据中心的小型办公室或机柜中运行 GPU 服务器吗?
A:可以。通过围绕电源、冷却和空间进行适当的规划设计,高性能 GPU 系统可以在小型数据中心、小型房间甚至机柜中可靠运行,或者直接选择我们的静音液冷工作站。(点击图片查看具体介绍)

Q:在本地运行高性能 GPU 系统需要什么样的电源设置?
A:使用带有 20A 或 30A 断路器的电路。避免多 GPU 服务器时使用普通办公插座。计量 PDU(配电装置)、UPS(不间断电源)和浪涌保护至关重要。
Q:我可以将住宅电源电路用于企业级服务器吗?
A:单 GPU 工作站可以在 15A 或 20A 线路上工作,但多 GPU 工作站或机架式服务器在负载下会可能超过该功耗。不要在共享住宅电路上运行它们。
Q:在小规模部署中,我应该包括什么样的远程管理工具?
A:寻找支持 IPMI 或 BMC 的服务器,并通过 LtHCS 或 LtMON 等管理软件进行管理。方便您远程重启、监控温度和更新固件,而无需对机柜中的系统进行物理维护。联系联泰集群了解更多信息。
Q:我如何决定在部署中使用哪些 GPU?
A:从你的工作量开始。一旦您评估了工作负载性能需求,请将其与空间、热量和可用功率相平衡。对于 CFD 和模拟,请使用具有强大 FP64 的 GPU,如NVIDIA H 系列 NVL。对于渲染和可视化,请使用具有视频编码和解码功能的 GPU,如 RTX PRO 6000 Blackwell。对于可并行化的低强度工作负载,请使用多个中间层 GPU。
GPU 服务器不是必须要一个完整的数据中心。如果工作负载需要电力和控制,机柜或小型设备室可以通过适当的规划来工作。
选择正确的机柜和机架。了解您的电源限制或安装大功率插座。确保有适当的气流进行冷却。规划远程管理和网络,以简化服务器设置。
人工智能原型和部署、工程仿真团队和生命科学研究实验室可以通过正确的构建在本地运行真正的 GPU 基础设施。如果您需要帮助为您的空间和工作负载设计 GPU 算力系统,联泰集群的专家们可以帮助您完成配置、构建、交付和部署过程。




相关贴子
-
 技术分享
技术分享基于 LoRA 技术的人工智能模型微调
2025.12.05 48分钟阅读 -
 技术分享
技术分享从‘专用’到‘真共享’:高校算力资源孤岛破冰全纪实
2025.05.09 37分钟阅读 -
 技术分享
技术分享利用 Oracles 和实验反馈指导生成式分子设计
2025.04.03 66分钟阅读