
博客
人工智能与大模型
异构集群助力全球车厂智驾升级
2025.04.25
22分钟阅读

某科技公司专注提供全球国际车厂高级辅助驾驶系统解决方案及各种车用电子产品。我们本次的项目便是为其自动驾驶控制系统定制搭建高性能、高扩展的人工智能训练平台。通过人工智能应用整合摄像头、倒车雷达、微波雷达等多种感测器数据,取得更精准的道路信息,实现更高端的自动驾驶功能。
-
管理节点:1 台双路 Intel® Xeon® CPU 4314 16 核心管理服务器;
-
计算节点:3 台双路 AMD Rome 7H12 64 个 核心 4 GPU 卡服务器(NVIDIA Ampere 架构 80GB);
-
网络部分:千兆交换机 1 台, 200GbE IB 交换机 1 台;
-
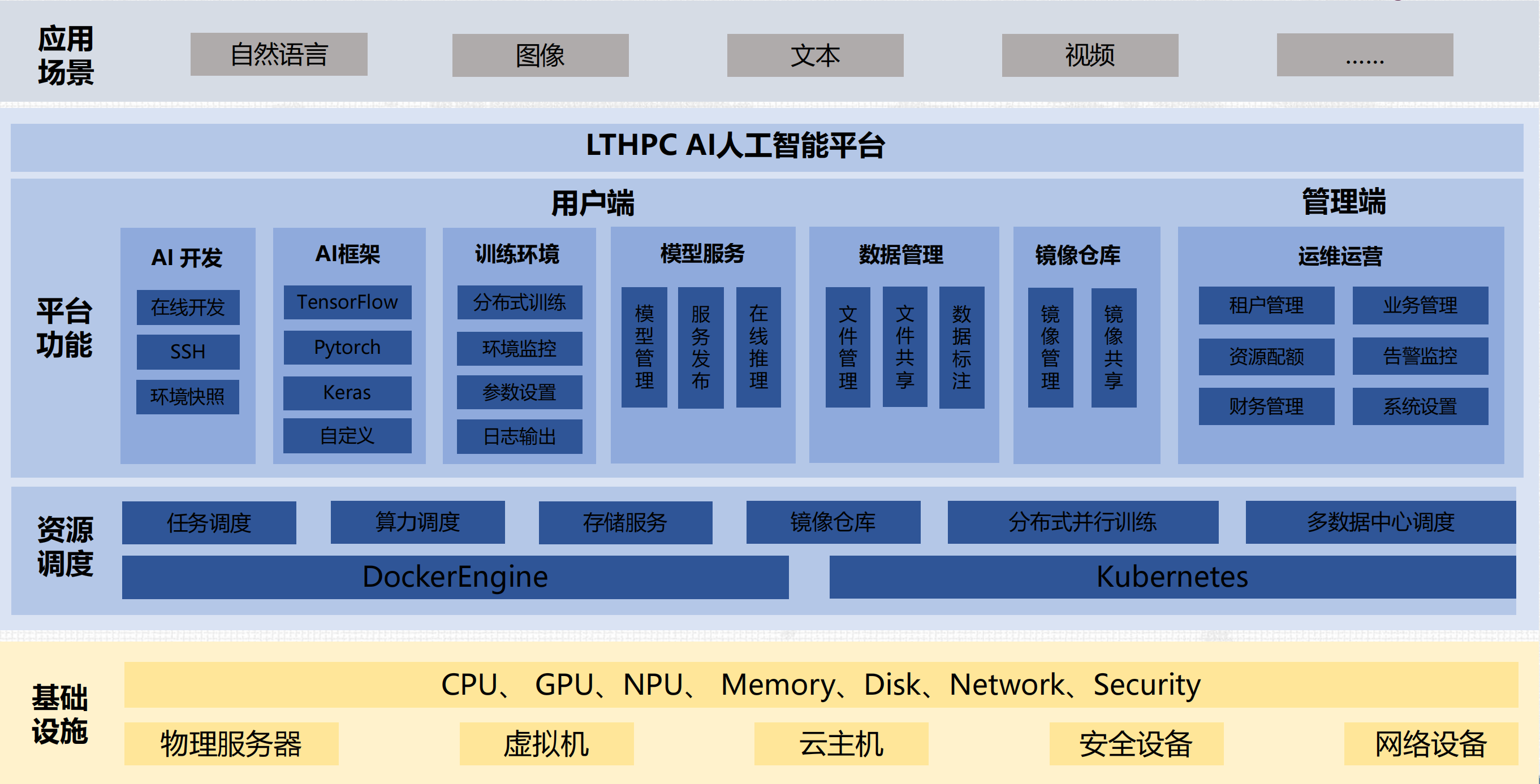
集群管理:LtAI 异构资源管理平台,搭建统一 AI 计算资源池;
-支持资源调度、监控、管理;
-支持组织、用户管理;
-支持存储管理,将各节点的本地存储组成分布式存储使用;
-支持数据标注;
-支持数据管理;
-支持模型训练、模型管理、模型服务;
-支持开发环境管理,各种AI框架;
-支持 AutoML 超参调优;






相关贴子
-
 人工智能与大模型
人工智能与大模型如何提高 RAG 模型的性能
2024.10.25 36分钟阅读 -
 人工智能与大模型
人工智能与大模型监测和改善深度学习的GPU使用情况
2022.07.14 0分钟阅读 -
 人工智能与大模型
人工智能与大模型LLMs 的历史与未来
2024.09.20 46分钟阅读