
博客
Keras 中的保存、加载和检查点深度学习模型

- 简介-在页面之间保持拇指
训练一个深度神经网络有时会以刚开始的速度结束。或者更糟的是,训练跑出现了分歧!这里有一个熟悉的场景:我们开始获得一个稳健的学习曲线,损失单调减少,训练和测试集性能几乎没有差异,做出一些巧妙的改变,却发现训练失败了。
如果我们没有从事情发展的时候开始记录检查点,我们肯定希望我们有。为此,我们需要一种适合您场景的日志检查点策略。Keras 是 TensorFlow 的高级 API,通过内置的检查点回调,可以轻松跟踪模型版本。然而,记录太多检查点仍然存在权衡,在某些情况下,用户仍然希望对其模型使用手动保存。
在本文中,我们将讨论在使用 Keras 时保存和恢复模型的三种主要方法,并举例讨论何时以及为什么选择每种方法。
探索模型检查点策略的试验台
在本教程中,我们将使用一个简单的图像分类训练运行作为测试台,以试验在训练期间保存、加载和自动记录检查点的不同方法。要创建一个新的虚拟环境(在 Linux 上使用 virtualenv):
virtualenv tf_checkpoints –python=python3.8 source tf_checkpoints/bin/activate
已经设置了 TensorFlow 2.xx 虚拟环境的读者只需激活即可立即开始。唯一的依赖项如下:
pip install tensorflow tensorflow_datasets matplotlib jupyter # only needed to save the model in TensorFlow JS format pip install tensorflowjs
请随意从 GitHub 上的存储库中提取我们将在示例中使用的所有代码:
git clone git@github.com:riveSunder/tf_keras_checkpoints.git
也可以作为托管在 Kaggle 上的 Jupyter 笔记本从头到尾运行本教程的代码。对于那些没有本地 GPU 可供训练但需要 Kaggle 帐户的读者来说,这是一个很好的选择。我们使用的数据集足够小,可以在笔记本电脑上进行训练,尽管速度不如 GPU。
首先,我们将介绍用于训练的通用框架,以及稍后将介绍的所有不同的检查点方法。第一,进口:
import os import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense,\ Dropout, \ ELU, \ Softmax, \ Flatten import tensorflow_datasets as tfds import matplotlib.pyplot as plt
接下来,我们有一个最小数量的超参数,如果需要,可以更改。默认情况下,我们使用的是 TensorFlow 数据集中提供的一个更简单的数据集。这些数据集可以快速轻松地进行训练,因此我们将能够专注于手头的主题:检查点。
model_iteration = 0 number_epochs = 32 batch_size = 2 my_lr = 3e-4 easy_mode = False if easy_mode: dataset_name = "rock_paper_scissors" else: dataset_name = "beans" model_name = "mobilenet"
“rock_paper_scissors”和“beans”数据集足够小和简单,可以在 0.90s 的高精度下通过短时间的训练来训练基本模型,非常适合我们的需求。我们将使用 MobileNet,这是一个特别有效的模型,只有几百万个参数,以预先训练的权重作为起点。
tensorflow_datasets 中的 _PrefetchDataset 对象没有直接插入 Keras 模型的拟合方法中,所以我们将其转换为一个这样的形式。辅助函数 tfds_to_numy 将 _PrefetchDataset 对象作为输入,并将输入数据和输出标签作为 numpy 数组返回。请注意,这个快捷方式对我们的教程来说很方便,但它依赖于数据集是否足够小以适应内存。
def tfds_to_numpy(dataset): train_np_iterator = tfds.as_numpy(dataset) train_x = None train_y = None for elem in train_np_iterator: image = elem["image"].reshape(-1, *elem["image"].shape) label = elem["label"].reshape(1) if train_x is None: train_x = image train_y = label else: train_x = np.append(train_x, image, 0) train_y = np.append(train_y, label, 0) return train_x, train_y
我们还将使用一个助手函数来实例化具有 MobileNet 基础的模型,以进行特征提取。辅助函数向基本模型添加一个顶部为3个具有指数线性单位的密集层。请注意,该函数以每个隐藏层的神经节点数量为输入,因此我们可以尝试具有不同密集层大小的模型。默认情况下,不训练 MobileNet 的基本参数。
def initialize_model(number_classes, \ input_shape, hidden_dims=64, \ my_lr=my_lr, trainable_base=False): tf.random.set_seed(13) np.random.seed(13) extractor = tf.keras.applications.MobileNet(\ input_shape=input_shape, include_top=False,\ weights="imagenet") # Set to True to also train the feature extraction layers extractor.trainable = trainable_base model = Sequential([extractor, \ Flatten(), \ Dropout(0.25), \ Dense(hidden_dims, \ kernel_regularizer=l2(3e-4),\ bias_regularizer=l2(1e-3)), \ ELU(), \ Dropout(0.25), \ Dense(hidden_dims, \ kernel_regularizer=l2(3e-4),\ bias_regularizer=l2(1e-3)), \ ELU(), \ Dense(number_classes), Softmax() ]) example_output = model(np.random.rand(1,*input_shape)) my_loss = tf.keras.losses.SparseCategoricalCrossentropy() model.compile(optimizer = "adam", \ loss=my_loss, \ metrics = ["accuracy"] \ ) model.optimizer.lr = my_lr return model
另一个辅助功能提供了一种快速可视化训练跑步的方法。
def visualize_history(history, save_figure=False): # Visualize Training my_cmap = plt.get_cmap("magma") loss_color = my_cmap(16) val_loss_color = my_cmap(64) my_cmap = plt.get_cmap("viridis") acc_color = my_cmap(128) val_acc_color = my_cmap(192) fig, ax = plt.subplots(1,1, figsize=(8,4)) ax_twin = ax.twinx() ax.plot(history.history["loss"], \ color=loss_color, label="training loss") ax.plot(history.history["val_loss"], \ color=val_loss_color, label="validation loss") ax.set_ylabel("Loss") ax.set_yticks(np.arange(0,4.0,0.5)) ax_twin.plot(history.history["accuracy"],\ color=acc_color, label="training accuracy") ax_twin.plot(history.history["val_accuracy"], \ color=val_acc_color, label="validation accuracy") ax_twin.set_ylabel("Accuracy") ax_twin.set_yticks(np.arange(0,1.0,0.1)) ax.legend(loc=6) ax_twin.legend(loc=5) plt.show()
有了我们的助手功能,我们现在可以开始进行培训了。我们将使用几个不同的目录来保存模型和模型权重。如果这些还不存在,下面的代码将生成它们。
# Directory for saving model as SavedModel saved_model_dir = os.path.join(\ "..", "models", f"{dataset_name}_{model_name}"\ f"{model_iteration:03}") if os.path.exists(saved_model_dir): while os.path.exists(saved_model_dir): model_iteration += 1 saved_model_dir = os.path.join(\ "..", "models", f"{dataset_name}_{model_name}"\ f"{model_iteration:03}") else: os.system(f"mkdir {saved_model_dir} -p") # Directory for saving model using BackupAndRestore saved_backup_dir = os.path.join(\ "..", "backups", f"{dataset_name}_{model_name}\ f"{model_iteration:03}") if os.path.exists(saved_backup_dir): while os.path.exists(saved_backup_dir): model_iteration += 1 saved_backup_dir = os.path.join(\ "..", "backups", f"{dataset_name}_{model_name}"\ f"{model_iteration:03}") else: os.system(f"mkdir {saved_backup_dir} -p") saved_backup_path = os.path.join(saved_backup_dir, "backup_{epoch:03d}_{val_loss:.2f}.ckpt") # Directory for saving weights (only) saved_weights_dir = os.path.join(\ "..", "weights", f"{dataset_name}_{model_name}"\ f"{model_iteration:03}") if os.path.exists(saved_weights_dir): while os.path.exists(saved_weights_dir): model_iteration += 1 saved_weights_dir = os.path.join(\ "..", "weights", f"{dataset_name}_{model_name}"\ f"{model_iteration:03}") else: os.system(f"mkdir {saved_weights_dir} -p") saved_weights_path = os.path.join(saved_weights_dir, "checkpoint_{epoch:03d}_{val_loss:.2f}.hdf5")
现在,我们可以开始构建回调,以便与 Keras 中的fit方法一起使用。在第一种情况下,我们不会使用任何自动检查点策略,只包括学习率调度器和 tensorboard 回调。这模仿了深度学习从业者可能处于构建模型和训练代码的早期阶段,并跳过了包括检查点回调(而是依靠手动保存权重)的场景。
# Callbacks # Defining a deliberately deleterious learning rate scheduler def scheduler(epoch, lr, epochs=number_epochs): if epoch <= max([1, epochs - epochs // 4]): return lr * 0.9 else: return lr * 20. tensorboard_callback = tf.keras.callbacks.TensorBoard(\ log_dir="logs", \ write_graph=False, \ update_freq='epoch', \ ) lr_callback = tf.keras.callbacks.LearningRateScheduler(scheduler) basic_callbacks = [tensorboard_callback, lr_callback]
接下来,从 tensorflow_dataset 加载数据集训练和测试拆分。然后,我们将 _PrefetchDataset 对象转换为 numpy 数组。
train_dataset = tfds.load(dataset_name, split="train", shuffle_files=True) test_dataset = tfds.load(dataset_name, split="test", shuffle_files=True) test_x, test_y = tfds_to_numpy(test_dataset) print(test_x.shape) train_x, train_y = tfds_to_numpy(train_dataset) print(train_x.shape)
使用来自训练数据集的样本,我们根据输入维度和训练样本中标签的数量实例化模型。
image = train_x[:1] number_classes = np.max(train_y)+ 1 input_shape = image.shape[1:] model = initialize_model(number_classes, input_shape) model.summary()
- 手动保存和加载权重
最简单的策略是在训练完成后手动保存模型权重。首先,我们初始化模型。我们前面定义的 helper 函数返回一个已经编译过的模型,因此我们可以立即调用fit方法。我们将只为第一种方法训练5个时期。
model = initialize_model(number_classes, input_shape) history = model.fit(x=train_x, y=train_y, \ validation_split=0.1, \ batch_size=batch_size, epochs=5, \ callbacks=basic_callbacks)
在模型训练到最后一个历元后,我们可以使用我们的助手功能可视化这次跑步的训练历史:
visualize_history(history)
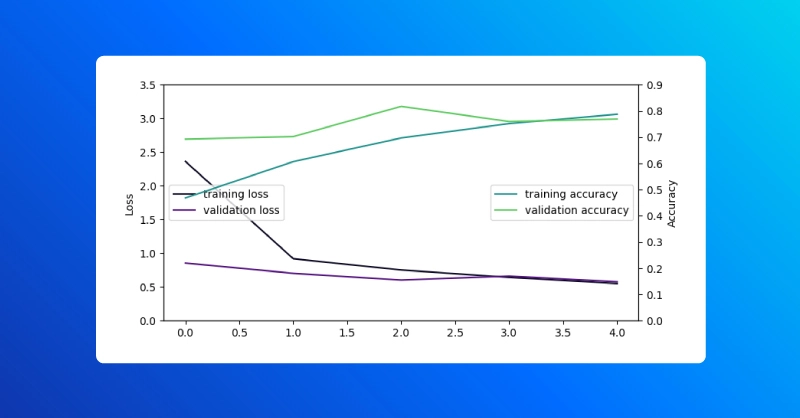
Keras Model 类中的 save_wights 和 load_weights 方法有助于手动保存和加载模型参数。然后,我们使用评估模型方法来比较加载训练权重之前和之后的模型。
# Save model weights manually weights_path = f"manual_weights{model_iteration:03}.ckpt" model.save_weights(os.path.join(saved_weights_dir, weights_path)) loss, accuracy = model.evaluate(test_x, test_y, \ batch_size=batch_size) print(f"model loss: {loss:.3e}, accuracy: {accuracy:.3f}") model = initialize_model(number_classes, input_shape) loss, accuracy = model.evaluate(test_x, test_y, \ batch_size=batch_size) print(f"newly instantiated model loss: {loss:.3e},"\ f" accuracy: {accuracy:.3f}") model.load_weights(os.path.join(saved_weights_dir, weights_path)) loss, accuracy = model.evaluate(test_x, test_y, \ batch_size=batch_size) print(f"model (weights loaded from disk) loss: {loss:.3e},"\ f" accuracy: {accuracy:.3f}") """ output: 64/64 [==============================] - 1s 11ms/step - loss: 0.4961 - accuracy: 0.8359 model loss: 4.961e-01, accuracy: 0.836 64/64 [==============================] - 1s 10ms/step - loss: 1.8674 - accuracy: 0.2969 newly instantiated model loss: 1.867e+00, accuracy: 0.297 64/64 [==============================] - 1s 10ms/step - loss: 0.4961 - accuracy: 0.8359 model (weights loaded from disk) loss: 4.961e-01, accuracy: 0.836 """
正如您在 evaluate 方法返回的结果中所看到的,在将参数保存并加载到新实例化的模型中后,它们与训练后立即用于原始模型的结果相同。
这种手动方法可能适用于开发的早期阶段,但正如我们将在接下来的几个会话中看到的那样,使用回调自动管理检查点会带来很多好处。
- 方法1:使用BackupAndRestore恢复中断的训练跑步
记录检查点的一个用例是从中断的培训会话中恢复。这可能是由于键盘中断(在调用 fit 之前忘记向模型添加关键细节)、本地工作站断电、云中过早终止的点实例或许多其他原因造成的。
BackupAndRestore 回调保存检查点(通常每次都覆盖旧的检查点),并允许您的模型从停止的地方恢复。
# A callback to interrupt training, # to demonstrate BackupAndRestore utility class Interrupt(tf.keras.callbacks.Callback): def on_epoch_begin(self, epoch, logs=None): if epoch == 4: print("\n Interrupting callback") raise RuntimeError("Interrupting callback who?") interrupt_callback = Interrupt() callbacks_with_interrupt = basic_callbacks + [interrupt_callback] model = initialize_model(number_classes, input_shape) try: history = model.fit(x=train_x, y=train_y, \ validation_split=0.1, \ batch_size=batch_size, epochs=15, \ callbacks=callbacks_with_interrupt) except: pass history = model.fit(x=train_x, y=train_y, \ validation_split=0.1, \ batch_size=batch_size, epochs=15, \ callbacks=basic_callbacks) """ output: … Epoch 4/15 465/465 [==============================] - 6s 13ms/step - loss: 0.8091 - accuracy: 0.6828 - val_loss: 0.6051 - val_accuracy: 0.7500 - lr: 1.9683e-04 Interrupting callback Epoch 1/15 465/465 [==============================] - 6s 13ms/step - loss: 0.6791 - accuracy: 0.7624 - val_loss: 0.7334 - val_accuracy: 0.6923 - lr: 1.5943e-04 Epoch 2/15 465/465 [==============================] - 6s 13ms/step - loss: 0.5904 - accuracy: 0.7860 - val_loss: 0.7615 - val_accuracy: 0.7212 - lr: 1.4349e-04 Epoch 3/15 … """
我们可以看到,在原始fit调用被回调中断后启动 fit 方法后,训练从 epoch 1开始。
如果我们包括 BackupAndRestore 回调,训练可以在中断后重新开始。此回调存储的备份包括优化器状态、存储权重和记住训练结束时的历元。
number_batches = train_x.shape[0] epoch_frequency = 3 # This is where we will define a BackupAndRestore callback backup_callback = tf.keras.callbacks.BackupAndRestore( \ saved_backup_dir, \ save_freq = number_batches*epoch_frequency, \ delete_checkpoint = True, \ save_before_preemption = False ) callbacks_with_backup = callbacks_with_interrupt + [backup_callback] model = initialize_model(number_labels, input_shape) try: history = model.fit(x=train_x, y=train_y, \ validation_split=0.1, \ batch_size=batch_size, \ epochs=5, \ callbacks=callbacks_with_backup) except: pass history = model.fit(x=train_x, y=train_y, \ validation_split=0.1, \ batch_size=batch_size, \ epochs=5, \ callbacks=basic_callbacks) """ output: … Epoch 4/15 465/465 [==============================] - 6s 14ms/step - loss: 0.6736 - accuracy: 0.7022 - val_loss: 0.7657 - val_accuracy: 0.6538 - lr: 1.9683e-04 Interrupting callback Epoch 5/15 465/465 [==============================] - 6s 13ms/step - loss: 0.5869 - accuracy: 0.7656 - val_loss: 0.7563 - val_accuracy: 0.6154 - lr: 1.5943e-04 Epoch 6/15 465/465 [==============================] - 6s 13ms/step - loss: 0.4990 - accuracy: 0.7796 - val_loss: 0.9010 - val_accuracy: 0.6250 - lr: 1.4349e-04 Epoch 7/15 """
与之前中断的训练运行不同,BackupAndRestore 回调使我们的模型能够从上一个备份检查点重新开始。
- 方法2:使用ModelCheckpoint回调
我们将研究的下一种保存和加载模型的方法可能是最方便的,主要是自动的,并且将满足您在很大一部分训练场景中跟踪模型参数的需求。
该方法依赖于 ModelCheckpoint 回调,并与 Keras 中的高级匹配API完美配合,无论是否合并其他回调(例如用于将训练信息记录到可视化仪表板的 tensorboard 回调)。
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint( saved_weights_path, \ save_freq = "epoch", \ monitor = 'val_accuracy', \ save_weights_only = True, \ verbose = 1) callbacks_with_checkpoints = basic_callbacks + [checkpoint_callback] model = initialize_model() history = model.fit(x=train_x, y=train_y, \ validation_split=0.1, \ batch_size=batch_size, epochs=number_epochs, \ callbacks=callbacks_with_checkpoints) visualize_history(history)
学习率回调是故意破坏的:在一定数量的时期后,学习率会增长,而不是继续衰减。结果,损失激增,模型对其任务变得完全无用。
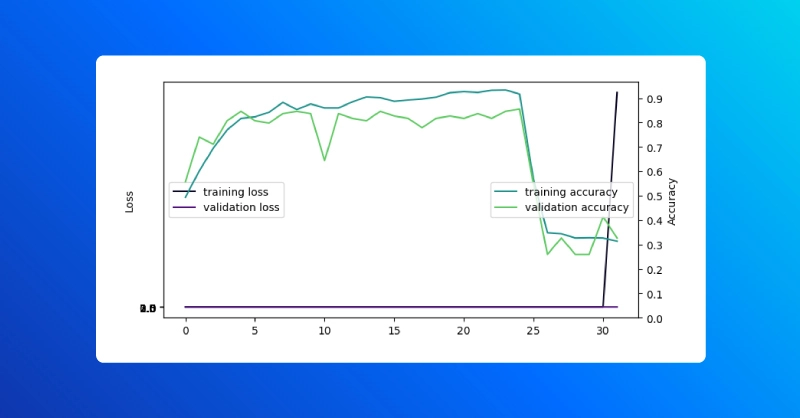
如果我们检查训练曲线,我们可以在学习率调度器开始提高学习率之前,找出性能良好的最后一个历元。这种错误很容易由打字错误或其他错误引起(想想乘以20而不是除法)。
# Restore checkpoint with best performance # add checkpoint with good performance good_checkpoint = 24 chkpt_listdir = os.listdir(saved_weights_dir) for elem in chkpt_listdir: if f"checkpoint_{good_checkpoint:03}" in elem and "index" not in elem: print(elem) load_it = elem loss, accuracy = model.evaluate(test_x, test_y, \ batch_size=batch_size) print(f"model (final training step) loss: {loss:.3e}, "\ f"accuracy: {accuracy:.3f}") good_checkpoint_path = os.path.join(saved_weights_dir, load_it) model.load_weights(good_checkpoint_path) loss, accuracy = model.evaluate(test_x, test_y, \ batch_size=batch_size) print(f"model (loaded from last good checkpoint) loss: {loss:.3e}, "\ f"accuracy: {accuracy:.3f}") """ output: checkpoint_024_0.94.hdf5 64/64 [==============================] - 1s 10ms/step - loss: 267607198400512.0000 - accuracy: 0.3359 model (final training step) loss: 2.676e+14, accuracy: 0.336 64/64 [==============================] - 1s 10ms/step - loss: 0.6853 - accuracy: 0.8281 model (loaded from last good checkpoint) loss: 6.853e-01, accuracy: 0.828 """
使用 ModelCheckpoint 回调自动记录(仅限权重)检查点时,可以轻松恢复以前记录的一组模型参数。也就是说,您可以将权重加载到具有完全相同架构的模型中。
另一方面,如果您一直在尝试架构超参数,并将模型的几个不同版本保存到磁盘上,其中一些可能在每一层的维度上都不匹配。
如果我们试图将以前记录的检查点加载到一个与以前几乎但不完全相同的架构的模型中,会发生什么?
# Save model weights and architecture in SavedModel format # If we change the model architecture # b
ut try to load the weights we saved before wrong_model = initialize_model(number_classes, input_shape, hidden_dims=256) print("Trying to load weights, into an architecture that does not match") try: wrong_model.load_weights(good_checkpoint_path) except: print(f"Model failed to load from {good_checkpoint_path}") """ output: Trying to load weights, into an architecture that does not match Model failed to load from ../weights/beans_mobilenet000/checkpoint_024_0.94.hdf5 """
该模型无法加载我们之前保存的权重。在这种情况下,每个密集隐藏层中的节点数量不匹配(256对128),并且该过程抛出异常。
- 方法3:以 TF SavedModel 格式保存模型配置和权重
在这种情况下,将整个模型保存为 SavedModel 格式可能很有用。当我们从完整的模型中保存和加载时,我们不会遇到使用错误的参数检查点体系结构实例化模型的问题。
model.save(saved_model_dir) print("model saved") loss, accuracy = model.evaluate(test_x, test_y, \ batch_size=batch_size) print(f"model that was saved to SavedModel directory, loss: "\ f"{loss:.3e}, accuracy: {accuracy:.3f}") restored_model = tf.keras.models.load_model(saved_model_dir) print("model restored") loss, accuracy = restored_model.evaluate(test_x, test_y, \ batch_size=batch_size) print(f"restored from SavedModel directory, loss: {loss:.3e}, "\ f" accuracy: {accuracy:.3f}") """ output: model saved 64/64 [==============================] - 1s 10ms/step - loss: 0.6853 - accuracy: 0.8281 model that was saved to SavedModel directory, loss: 6.853e-01, accuracy: 0.828 model restored 64/64 [==============================] - 1s 10ms/step - loss: 0.6853 - accuracy: 0.8281 restored from SavedModel directory, loss: 6.853e-01, accuracy: 0.828 """
除了避免如上所述的错误指定体系结构的问题外,以SavedModel格式保存Keras模型还可以在将模型转移到生产环境中时实现许多附加功能。
例如,我们可以将 SavedModel 转换为 TensorFlow Lite 格式。TF-Lite 模型在磁盘上占用的空间更少,并利用更高效的运算符进行推理,从而促进了在手机和边缘设备上的本地执行。下面显示了如何从 SavedModel 目录转换 Keras 模型以生成 TF-Lite 版本的示例。
然后,我们可以使用下面的评估循环来检查模型是否保持其原始性能。
correct_lite = 0 total_samples = test_x.shape[0] for my_index in range(test_x.shape[0]): dtype = input_details[list(input_details.keys())[0]]["dtype"] my_batch = np.array(test_x[my_index:my_index+1], dtype=dtype) full_output_data = model(my_batch) input_name = list(input_details.keys())[0] output_name = list(output_details.keys())[0] output_data = tf_lite_signature(**{input_name: my_batch})[output_name] true_label = test_y[my_index] correct_lite += 1.0 * (output_data.argmax() == true_label) accuracy_lite = correct_lite / total_samples print(f"TF Lite test accuracy: {accuracy_lite}") """ output: TF Lite test accuracy: 0.828125 """
为了部署在浏览器中运行的小型模型,您可能有兴趣将Keras模型转换为 TensorFlow JavaScript 格式。这将模型分割成更小的部分,并使用可与 JavaScript 一起使用的格式。
# to install tensorflowjs: # ! pip install tensorflowjs import tensorflowjs as tfjs # convert from the keras model directly tfjs.converters.save_keras_model(model, "tfjs_from_model") # convert from the SavedModel directory tfjs.converters.convert_tf_saved_model(saved_model_dir, "tfjs_from_saved_model") # Check the contents of the tfjs directories ! ls tfjs_from_model ! ls tfjs_from_saved_model
使用 TensorFlow JS 进行浏览器部署超出了本教程的范围,但有关更多信息,请查看官方文档。
Keras 中的深度学习模型检查点方法
在本文中,我们探讨了使用手动保存和自动检查点回调来保存训练进度的几种不同方法。有效的检查点策略不仅有助于避免失去来之不易的训练进度的痛苦陷阱,而且以正确的格式保存模型(如 SavedModel)可以使迭代开发和架构探索更容易,并有助于进一步细化模型,以便部署到边缘设备或 web 浏览器。
训练一个深度学习模型需要宝贵的时间,失去进展可能会带来令人沮丧的挫折和更长的完成时间。开发和训练这些综合模型所面临的挑战和消耗时间是巨大的,联泰集群提供了广泛的GPU加速工作站、服务器和全方位解决方案,以帮助加快研究。立即联系我们,了解更多信息,并获得下一个专门构建的可定制系统的正式报价。





相关贴子
-
 人工智能与大模型
人工智能与大模型联泰集群 W7系列 液冷工作站:AI 训练不卡壳、模型出得快,这才是 AI 团队该有的算力神器
2025.12.26 13分钟阅读 -
 人工智能与大模型
人工智能与大模型AlphaFold 3-扩散彻底改变了分子结构预测
2024.08.09 22分钟阅读 -
 人工智能与大模型
人工智能与大模型什么是 LLM 蒸馏与量化
2025.05.16 31分钟阅读