
博客
LLMs 的历史与未来
大型语言模型的创建并非一蹴而就。值得注意的是,语言模型的第一个概念始于被称为自然语言处理的基于规则的系统。这些系统遵循预定义的规则,根据文本输入做出决策并推断结论。这些系统依赖于 if-else 语句处理关键字信息并生成预定输出。想象一个决策树,如果输入包含 X、Y、Z 或没有,则输出是预定的响应。例如:如果输入包含关键字“mother”,则输出“How is your mother?”否则,输出“你能详细说明一下吗?”
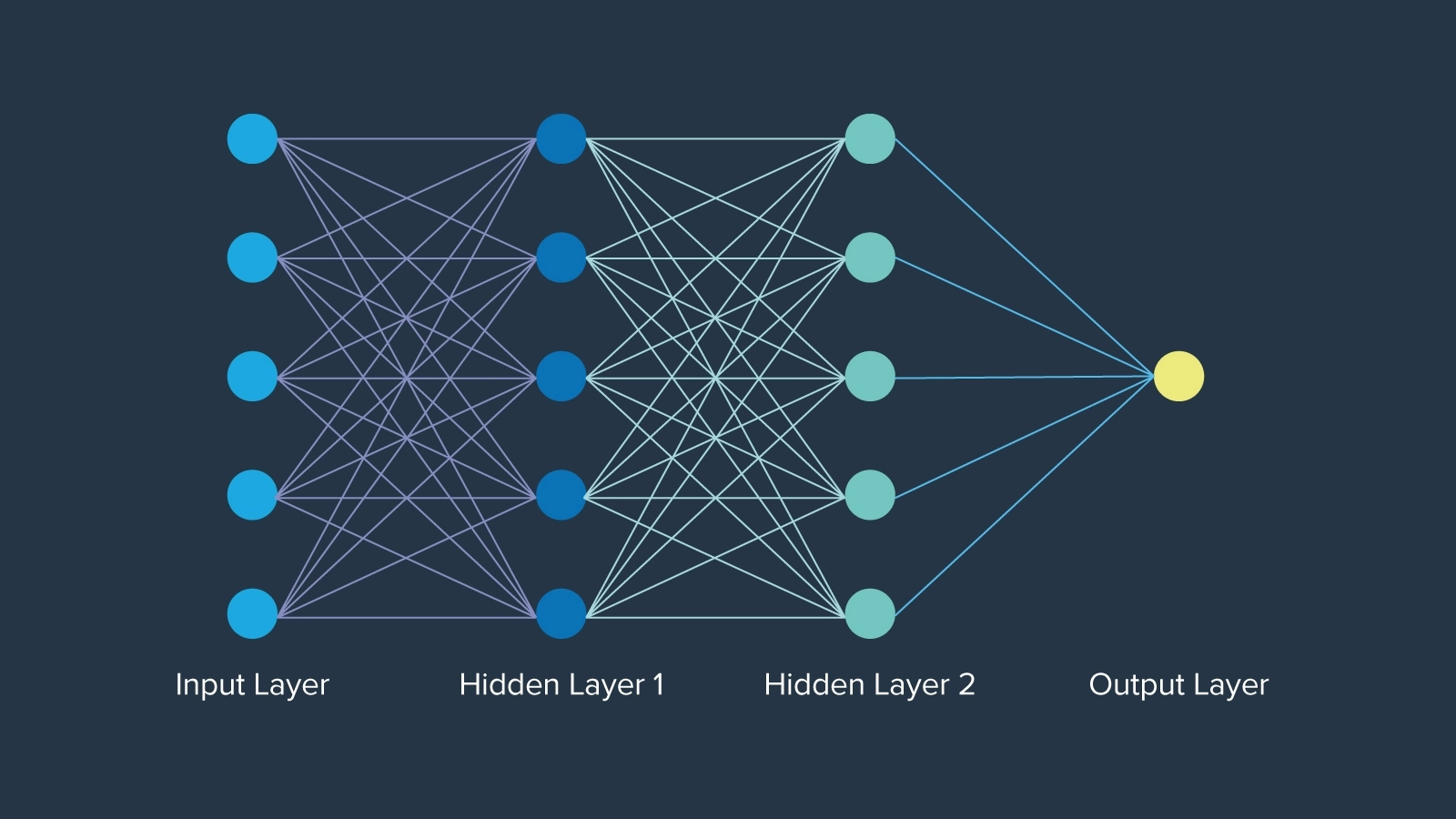
最大的早期进步是神经网络,1943年数学家沃伦·麦库洛克首次引入神经网络时,受到了人类大脑功能神经元的启发。神经网络甚至比“人工智能”一词早了大约12年。每一层的神经元网络都是以特定的方式组织的,每个节点都有一个权重,决定了它在网络中的重要性。最终,神经网络打开了紧闭的大门,为人工智能的永久构建奠定了基础。
计算机无法像人类一样理解句子中单词的含义。为了提高语义分析的计算机理解能力,必须首先应用单词嵌入技术,该技术允许模型捕获相邻单词之间的关系,从而提高各种 NLP 任务的性能。然而,需要一种方法将单词嵌入存储在内存中。
长短期记忆(LSTM)和门控循环单元(GRU)是神经网络中的巨大飞跃,能够比传统神经网络更有效地处理序列数据。虽然 LSTM 不再被使用,但这些模型为更复杂的语言理解和生成任务铺平了道路,最终产生了转换器模型。
注意力机制的引入改变了游戏规则,使模型在进行预测时能够专注于输入序列的不同部分。Transformer 模型在2017年发表的开创性论文《Attention is All You Need》中引入,利用注意力机制同时处理整个序列,大大提高了效率和性能。八位谷歌科学家没有意识到他们的论文在创造当今人工智能方面会产生什么影响。
在这篇论文之后,谷歌的 BERT(2018)被开发出来,并被吹捧为所有 NLP 任务的基线,作为一个开源模型,用于许多项目,使人工智能社区能够构建项目并发展壮大。它的上下文理解技巧、预先训练的性质和微调选项,以及TF模型的演示,为更大的模型奠定了基础。
除了 BERT,OpenAI 还发布了 GPT-1,这是他们TF模型的第一次迭代。GPT-1(2018)从1.17亿个参数开始,其次是 GPT-2(2019),大幅跃升至15亿个参数,GPT-3(2020)的进展仍在继续,拥有1750亿个参数。OpenAI 基于 GPT-3 的开创性聊天机器人 ChatGPT 于两年后的2022年11月30日发布,标志着一场巨大的热潮,真正使强大的人工智能模型的访问民主化。了解 BERT 和 GPT-3 之间的区别。
硬件的进步、算法和方法的改进以及多模态的集成都有助于大型语言模型的进步。随着该行业找到有效利用 LLM 的新方法,持续的进步将针对每个应用程序量身定制,并最终彻底改变计算的格局。
硬件进展
改进 LLM 最简单直接的方法是改进模型运行的实际硬件。图形处理单元(GPU)等专用硬件的开发显著加速了大型语言模型的训练和推理。GPU 凭借其并行处理能力,对于处理 LLM 所需的大量数据和复杂计算至关重要。

TF架构以已经辅助 LLM 而闻名。这种架构的引入对 LLM 的发展至关重要,就像现在一样。它能够同时而不是顺序处理整个序列,极大地提高了模型的效率和性能。
话虽如此,我们仍然可以对TF架构以及它如何继续发展大型语言模型抱有更多期望。
对TF模型的不断改进,包括更好的注意力机制和优化技术,将导致更准确、更快的模型。
对稀疏变换器和高效注意力机制等新型架构的研究旨在降低计算要求,同时保持或提高性能。
多模态输入的集成
LLM 的未来在于其处理多模式输入的能力,整合文本、图像、音频和潜在的其他数据形式,以创建更丰富、更具情境感知的模型。OpenAI 的 CLIP 和 DALL-E 等多模态模型已经证明了结合视觉和文本信息的潜力,使图像生成、字幕等应用成为可能。
这些集成使 LLM 能够执行更复杂的任务,例如从文本和视觉线索中理解上下文,这最终使它们更加通用和强大。
这些进步并没有停止,随着 LLM 创建者计划在他们的工作中纳入更多创新技术和系统,还会有更多的进步。并非 LLM 的每一项改进都需要更苛刻的计算或更深入的概念理解。一个关键的改进是开发更小、更用户友好的模型。
虽然这些模型可能无法与 GPT-4 和 LLaMA 3 等“Mammoth LLM”的有效性相匹配,但重要的是要记住,并非所有任务都需要大量复杂的计算。尽管尺寸较大,但 Mixtral 8x7B 和 Mistal 7B 等先进的较小型号仍然可以提供令人印象深刻的性能。以下是一些有望推动 LLM 发展和改进的关键领域和技术:
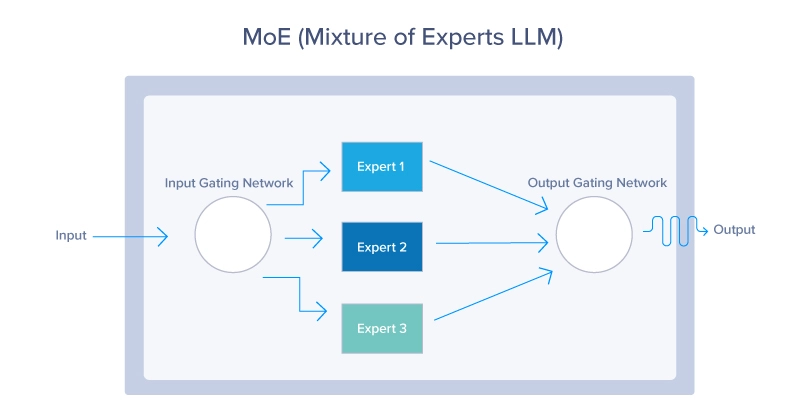
1.混合专家(MoE)
MoE 模型使用动态路由机制来为每个输入仅激活模型参数的子集。这种方法允许模型有效地扩展,根据输入上下文激活最相关的“专家”,如下所示。MoE 模型提供了一种在不增加计算成本的情况下扩大 LLM 的方法。通过在任何给定时间只利用整个模型的一小部分,这些模型可以使用更少的资源,同时仍然提供出色的性能。
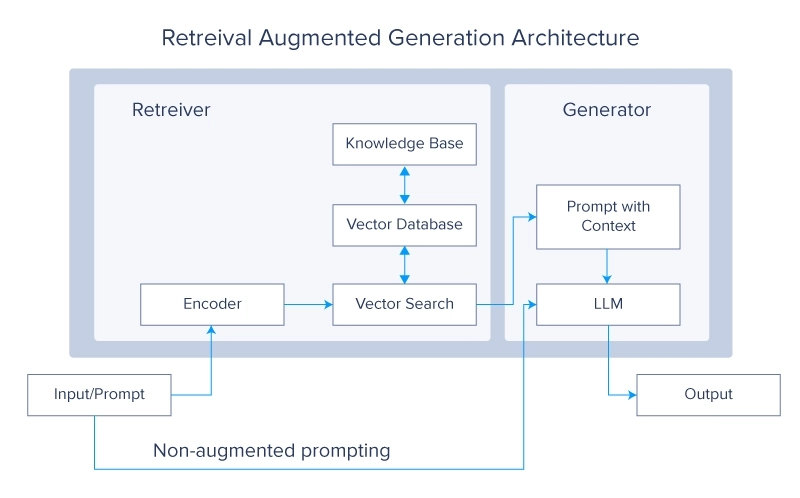
2.检索增强生成(RAG)系统
检索增强生成系统目前是 LLM 社区的一个非常热门的话题。这个概念质疑,当你可以简单地从外部源检索所需的数据时,为什么你应该在更多的数据上训练 LLM。然后,这些数据用于生成最终答案。
RAG 系统通过在生成过程中从大型外部数据库检索相关信息来增强 LLM。这种集成使模型能够访问和整合最新和特定领域的知识,提高其准确性和相关性。将 LLM 的生成能力与检索系统的精度相结合,形成了一个强大的混合模型,可以生成高质量的响应,同时保持对外部数据源的了解。
3.元学习
元学习方法允许 LLM 学习如何学习,使他们能够在最少的训练下快速适应新的任务和领域。
元学习的概念取决于几个关键概念,例如:
-
少镜头学习:通过该方法,LLM 仅通过几个例子就可以理解和执行新任务,从而大大减少了有效学习所需的数据量。这使得它们在处理各种场景时具有高度的通用性和高效性。
-
自我监督学习:LLM 使用大量未标记的数据来生成标签并学习表示。这种形式的学习允许模型创建对语言结构和语义的丰富理解,然后针对特定应用进行微调。
-
强化学习:在这种方法中,LLM 通过与环境互动并接受奖励或惩罚形式的反馈来学习。这有助于模型优化其行为,并随着时间的推移改进决策过程。
LLM 是现代技术的奇迹。它们的功能复杂,体积庞大,在进步方面具有开创性。在这篇文章中,我们探讨了这些非凡进步的未来潜力。从人工智能领域的早期开始,我们还深入研究了神经网络和注意力机制等关键创新。
然后,我们研究了增强这些模型的多种策略,包括硬件的进步、内部机制的改进以及新架构的开发。到目前为止,我们希望您对 LLM 及其在不久的将来的发展轨迹有了更清晰、更全面的了解。





相关贴子
-
 人工智能与大模型
人工智能与大模型40 只“龙虾” + 全液冷!OpenClaw 全栈国产 AI 一体机 24 小时满负荷不宕机
2026.03.13 28分钟阅读 -
 人工智能与大模型
人工智能与大模型预告 | 联泰集群以算力即服务,引领智算集群全栈云服务新篇章,关注第六届中国超级算力大会
2024.11.08 11分钟阅读 -
 人工智能与大模型
人工智能与大模型联泰集群 W7系列 液冷工作站:AI 训练不卡壳、模型出得快,这才是 AI 团队该有的算力神器
2025.12.26 13分钟阅读