
博客
如何为 GPU 提供数据才是真正的 AI 瓶颈

Introduction
介绍
随着人工智能负载规模持续增长,部署高性能多 GPU 集群似乎成为获取更快洞察、构筑竞争优势的必然路径。然而,绝大多数人工智能或机器学习团队都无法充分利用手中的 GPU 资源 —— 峰值时段仅有 7% 的团队能将 GPU 利用率提升至 85% 以上,造成数百万美元的闲置硬件资源浪费。
真正的性能瓶颈并非 GPU 或 CPU,而是存储系统。当存储系统无法及时为 GPU 供给数据时,GPU 便会处于闲置状态,沦为吞噬成本的低效资产,既浪费宝贵的研发时间,也造成高价硬件资源的闲置。
在本地部署的人工智能系统中,想要最大化多 GPU 性能,就必须保障存储系统的最优吞吐量。若存储系统的数据供给速度跟不上 GPU 的处理速度,即便是最先进的硬件,也会变成昂贵的摆设,难以转化为真正的竞争优势。
核心要点总结
1.多数人工智能团队的 GPU 利用率低于 85%,根源在于存储系统的数据供给速度无法匹配 GPU 处理需求。
2.性能瓶颈不在 GPU,而在于存储吞吐量。
3.本指南将介绍面向不同场景的最优存储架构:
- 人工智能工作站:采用带独立磁盘冗余阵列(RAID)的本地非易失性内存主机控制器接口规范(NVMe)存储;
- 多 GPU 服务器:采用本地存储与共享存储相结合的混合架构,搭配 GPU 加速的 RAID 技术;
- 机柜级集群:采用并行文件系统,如 WEKA、Vdura 或 DDN。
4.存储系统必须作为人工智能系统的核心组成部分进行设计,其规模需与 GPU 数量成比例扩展,并持续监控运行状态,避免高价硬件资源闲置。
Why GPUs are So Hungry? Understanding the Storage Bottleneck
为何 GPU 如此 “渴求” 数据?解析存储瓶颈的本质
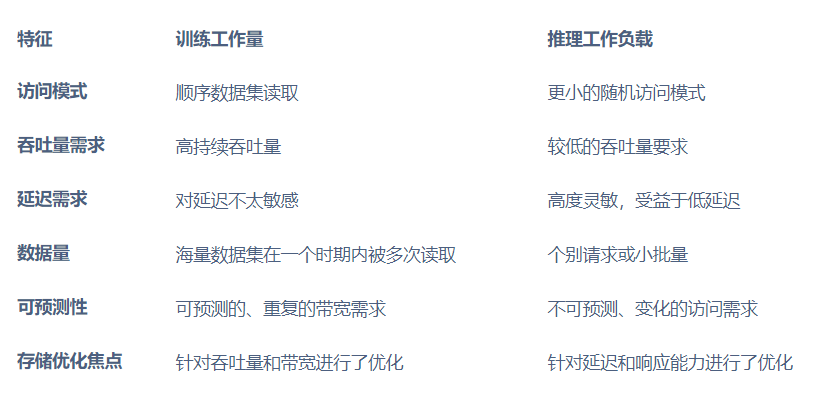
现代人工智能负载(如变换器模型训练、医疗影像领域的三维 U 型网络)会产生持续、海量的输入 / 输出(I/O)请求,对存储系统的压力远超传统企业级应用。
数据预处理的额外开销:在一轮完整的模型训练周期中,高达 65% 的时间可能耗费在图像变换、标记化处理、特征工程等任务上。这些操作需要反复从存储系统读取原始数据,若存储系统的数据供给速度不足,预处理流程会进一步变慢,形成恶性循环。
GPU 资源 “饥饿” 问题:当存储吞吐量无法匹配 GPU 的处理速度时,GPU 就会陷入等待数据的闲置状态。一旦利用率跌破 90%,就意味着算力周期被大量浪费 —— 哪怕是短暂的数据延迟,也会让高价硬件的宝贵计算时间白白流失。
上述两大瓶颈的根源完全一致:存储系统无法满足现代 GPU 的吞吐量需求。当存储系统的数据供给速度落后于 GPU 的处理速度时,不仅预处理任务耗时会延长,GPU 的等待时间也会增加,进而引发一系列连锁反应:
- 性能影响:模型训练速度大幅下降
- 经济影响:闲置的 GPU 直接导致经济损失,同时延缓模型上线部署进度
- 战略影响:存储瓶颈会让高额的 GPU 投资回报大打折扣
推理负载与训练负载的对比分析
Storage for GPU Workstations
面向 GPU 工作站的存储方案
人工智能工作站的存储方案,需兼顾性能可预测性、高性能和运维简洁性三大核心需求。多数场景下,本地存储是最优选择 —— 它能提供专属的吞吐量和低延迟,且不受共享基础设施性能波动的影响。在这一层级,理想的存储方案需在速度、容量、可靠性之间取得平衡,同时具备易部署、易管理的特性。
本地 NVMe 固态硬盘
- 核心优势:性能可预测、延迟低。本地 NVMe 固态硬盘可消除网络带来的性能瓶颈,提供稳定的存储性能,不受外部资源竞争的影响。
- 适用场景:本地推理任务、快速模型迭代、数据科学家处理本地容量可承载的数据集、对性能可复现性要求高于多用户访问需求的研发环境。
- 容量权衡:存储容量受限于工作站本身,针对大规模或长期运行的项目,需谨慎筛选数据集,并制定完善的外部备份策略。
工作站的 RAID 方案选型
- RAID 5:在性能与容错性之间实现高效的容量平衡,适合存储高价值数据集或训练检查点,且对冗余能力有中等需求的工作站场景。
- RAID 10:优先保障性能与数据弹性,适合涉及频繁检查点写入或存储不可替代数据的工作负载。
工作站层级的常见瓶颈
- 输入 / 输出操作数(IOPS)不足:由 NVMe 设备配置不足或使用消费级固态硬盘导致。建议部署 IOPS 指标达 50 万以上的企业级 NVMe 固态硬盘,并确保 PCIe 通道分配充足。
- 文件访问模式低效:部分框架缺乏完善的缓冲或缓存机制,会加剧随机输入 / 输出的额外开销。可通过优化数据加载器解决该问题,例如在 PyTorch 数据加载器中提高工作进程数(num_workers)、启用持久化工作进程(persistent_workers),或采用内存映射文件、缓存层减少重复的磁盘访问操作。
Storage for Multi-GPU Servers
向多 GPU 服务器的存储方案
多 GPU 服务器主要支撑以下场景:基于共享基础设施的团队协作、中等规模多 GPU 训练、共享模型仓库管理、面向多用户的生产级推理服务。
多 GPU 服务器的存储部署,需平衡本地存储的性能优势与共享存储的运维价值。最有效的架构设计是混合存储架构,既保留本地存储对 GPU 利用率的保障作用,又通过共享存储实现团队协作与数据集中管理。
本地存储 + 共享存储的混合架构
- 本地 NVMe 负责数据暂存与检查点存储:高速本地 NVMe 固态硬盘承担检查点写入与数据集临时暂存任务,避免在输入 / 输出密集型训练阶段给共享存储带来不必要的负载。
- GPU 加速的 RAID 技术:以 Graid Technology 为代表的解决方案,将 RAID 处理任务卸载至专用 GPU,性能可达传统硬件 RAID 的 10 倍。该技术仅适用于 NVMe 存储,可通过专用 GPU 加速器或软件抽象层实现(软件方案仅占用不到 2% 的 GPU 算力)。
- 共享存储支撑数据集管理与团队协作:集中化的数据集与模型工件存储,可消除服务器间的数据冗余拷贝,支持多用户访问,同时兼容 Kubernetes 或 Slurm 等调度系统的任务编排。但需注意,多进程并发读取同一数据集时,可能会产生一定的延迟。
服务器存储的其他关键考量
POSIX 兼容性:这是硬性要求,因为绝大多数人工智能框架都依赖标准的文件系统语义。同时,当大量 GPU 进程并发访问海量文件时,元数据的可扩展性也至关重要。
NVMe 网络存储(NVMe-oF):通过以太网、光纤或混合网络架构,将 NVMe 性能扩展至网络层面,实现接近本地 NVMe 水平的延迟与吞吐量,赋能共享存储场景。如需了解存储网络的更多细节,可咨询我们的工程师。
服务器层级的常见瓶颈
- 现代多 GPU 服务器通过 PCIe(在 HGX 和 DGX 部署环境中则搭配 NVLink 技术)实现内部高速数据传输。若存储系统未针对高吞吐量场景进行优化,很容易成为性能短板:
- 网络带宽饱和:当 GPU 集群的聚合数据需求超出存储网络的承载能力时,会引发网络拥塞。建议升级至高速网络架构(如 100GbE 以太网或无限带宽网络 InfiniBand),部署多路径存储网络实现负载分担,或单独部署存储专用网络,避免与计算业务流量产生竞争。
- 传统网络存储的并发能力限制:传统网络存储平台的设计无法适配人工智能并行工作负载。可采用 WEKA、VDURA 等并行文件系统提升并发访问效率,或部署本地 NVMe 缓存层,减少对共享存储的并发请求压力。
单一依赖传统网络附加存储(NAS)的风险:若在多 GPU 活跃训练场景中仅采用传统 NAS 存储,往往会导致 GPU 利用率低下、任务性能波动。我们建议采用 “本地 NVMe 支撑活跃训练 + 共享存储管理数据集与检查点” 的混合架构,同时确保存储网络带宽与 GPU 数量成比例扩展。
Storage for Rack-Scale AI Clusters
面向机柜级人工智能集群的存储方案
适用场景:基于数十甚至数百块 GPU 的大规模分布式训练、具备集中化管控能力的企业级人工智能平台、承载大量并发任务的科研或生产环境。
在机柜级集群的架构中,存储系统必须作为人工智能系统的有机组成部分进行一体化设计。GPU、网络、存储三者共同构成一个完整的性能闭环 —— 任何一个环节的性能滞后,都会导致 GPU 利用率急剧下降。
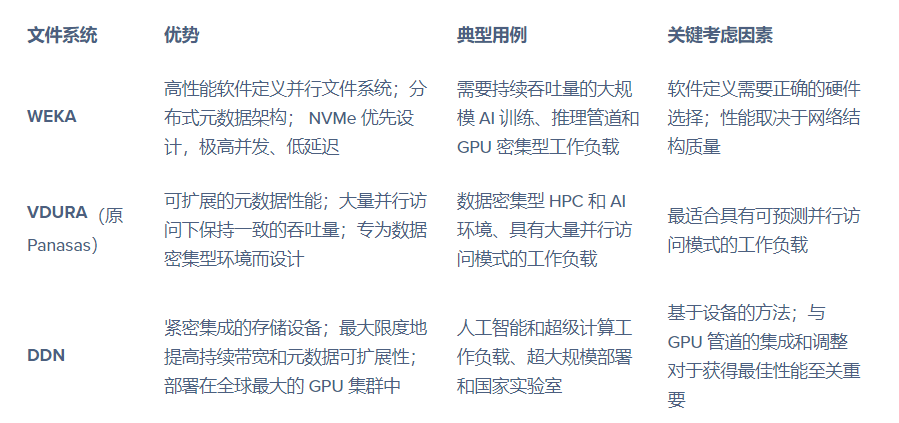
人工智能优化型并行存储平台
在这一层级,必须采用专为人工智能场景打造的并行存储平台,才能满足大规模 GPU 集群对聚合吞吐量与并发能力的严苛需求。
- WEKA:提供高性能的软件定义并行文件系统,针对人工智能与高性能计算负载深度优化。其分布式元数据架构与 NVMe 优先的设计,可支撑超高并发与低延迟访问,非常适合大规模训练与推理流水线。
- VDURA(原 Panasas):推出面向数据密集型高性能计算与人工智能场景的并行文件系统,重点优化元数据的可扩展性,确保在高并发访问压力下仍能维持稳定的吞吐量。
- DDN:提供高度集成的专用存储设备,专为人工智能与超级计算负载设计。DDN 存储平台聚焦于最大化持续带宽与元数据可扩展性,已广泛部署于全球多个超大规模 GPU 集群。
核心要点:尽管上述平台的架构设计各有差异,但机柜级集群的存储性能,并不取决于文件系统的品牌,而在于存储、网络与 GPU 数据流水线的整合与调优水平。
集群级架构的关键设计原则
将存储与 GPU 视为统一的设计问题:存储系统的选型与容量规划,需基于 GPU 数量、模型大小、数据集访问模式与预期并发量,而非简单参考通用的容量指标。
制定清晰的扩容规划:随着模型规模、数据集大小与任务并行度的提升,存储系统的容量与吞吐量必须同步扩展。
高速网络架构是硬性要求:必须部署高速互联技术(如无限带宽网络 InfiniBand 或 100GbE 及以上的以太网),防止存储流量成为分布式训练的主要性能瓶颈。
集群层级的常见瓶颈
- 任务启动阶段的元数据竞争:当数千个进程同时访问文件与目录时,易引发元数据访问冲突。可采用 WEKA、Vdura 等分布式元数据架构的并行文件系统,提升并发元数据处理能力,或通过元数据缓存策略缓解竞争压力。
- 网络带宽饱和:当 GPU 集群的聚合数据需求超出存储网络或交换机的承载能力时,会导致网络拥塞。建议升级高速网络架构,部署多路径存储网络实现负载分担。
- 聚合带宽不足:当存储节点或底层存储介质无法支撑集群级别的数据读取速率时,会限制整体性能。需根据 GPU 数量成比例扩展存储容量,确保存储节点能提供充足的聚合吞吐量。
全部署层级的通用最佳实践
无论部署规模大小,成功的人工智能存储架构都离不开持续监控、真实场景基准测试与主动优化。
- 定期开展 GPU 利用率基准测试:借助 NVIDIA 数据中心 GPU 管理器(DCGM)或 nvidia-smi 等工具,定期监测 GPU 利用率,在存储 I/O 相关的性能瓶颈影响生产训练任务前及时发现并解决。持续监控有助于区分计算密集型与 I/O 密集型负载,实现针对性优化。
- 基于真实负载监控存储吞吐量:避免单纯依赖无法反映真实人工智能训练模式的合成基准测试。真实负载测试应涵盖多 GPU 并发访问、典型批次大小与实际数据集特征,从而精准定位性能短板。
- 设计匹配模型 I/O 模式的数据流水线:通过合理的缓存、预取与数据加载策略优化数据流水线。对于访问模式可预测的训练负载,顺序预取策略效果显著;对于访问需求不可预测的推理负载,则需优化并行随机读取性能。
- 根据负载特征匹配存储方案:推理负载适合采用针对随机访问优化的低延迟存储,训练负载则需要高持续吞吐量的存储来支撑数据集顺序读取。准确把握负载特征,是做出合理存储架构决策的关键。
- 部署存储性能指标监控与告警机制:对吞吐量、延迟、队列深度、错误率等核心指标进行实时监控并设置告警阈值。主动监控可在存储性能下降影响 GPU 利用率与训练任务完成时间前,及时发现异常。
FAQ About AI Storage Infrastructure
人工智能存储基础设施常见问题解答
1.问:我的 GPU 性能足够支撑业务负载,但利用率始终偏低,原因何在?答:存储瓶颈是最常见的原因。当存储系统无法及时供给数据时,GPU 会处于等待状态。若 GPU 利用率持续低于 90%,则大概率是存储吞吐量不足导致的。
2.问:多 GPU 训练场景需要多大的存储吞吐量?答:具体数值取决于 GPU 数量、批次大小与数据预处理需求。作为基准参考,单块现代 GPU 在训练过程中的数据吞吐量需求约为 1-5GB/s,一套 8 卡 GPU 系统可能需要 10-40GB/s 的聚合存储吞吐量,才能避免性能瓶颈。
3.问:是否需要部署 WEKA、VDURA 或 DDN 这类并行文件系统?答:仅在机柜级集群(数十或数百块 GPU)场景下是必要的。对于工作站与小型多 GPU 服务器,本地 NVMe 或 NVMe-oF 共享存储已能满足需求。只有当聚合吞吐量需求超出传统存储系统的承载能力时,并行文件系统才成为必需。
4.问:应当优先升级 GPU 还是存储系统?答:若当前 GPU 利用率低于 90%,建议优先升级存储系统。在存储存在瓶颈的情况下,增加 GPU 只会造成更多资源浪费。相比购置新的 GPU,存储优化往往能以更低的成本,显著提升 GPU 利用率,实现更高的投资回报率。
Conclusion: The True Cost of Ignoring Storage
结论:忽视存储系统的真实代价
在人工智能部署中,忽视存储基础设施的需求会造成高昂的闲置 GPU 成本损失。如果没有高效、专用的存储后端提供持续的高吞吐量数据供给,即便是顶级的 GPU 硬件,性能也会大打折扣。一套因存储瓶颈导致利用率仅 50%、价值 5 万美元的 GPU 集群,其实际价值甚至低于一套规模更小、但存储配置合理、利用率达 90% 的集群。
即刻行动起来。借助 iostat、iotop 或 NVIDIA DCGM 等工具,对现有的 I/O 流水线进行基准测试,在扩容 GPU 前识别潜在的存储瓶颈。即使是对存储基础设施进行适度优化,也能以远低于购置新 GPU 的成本,大幅提升 GPU 利用率。
GPU 已然成为计算时代的焦点。选择联泰集群,我们将助力您的企业,为 GPU 计算架构匹配相适配的支撑组件,提供从配置、验证到交付的全流程服务,打造一套平衡、高效且可靠的存储解决方案,与计算系统协同运行。





相关贴子
-
 人工智能与大模型
人工智能与大模型联泰集群赋能四川某科大计算机学院 AI 科研平台,打造高性能 GPU 算力集群!
2024.12.20 27分钟阅读 -
 人工智能与大模型
人工智能与大模型DeepSeek 算力平台推荐方案
2025.02.14 116分钟阅读 -
 人工智能与大模型
人工智能与大模型一键托管,安全无忧 - 联泰集群 LtAIDC AI 应用广场正式发布
2026.06.19 14分钟阅读