
博客
深度学习指南:AI 模型中的冻结层技术

随着预训练模型的广泛使用,企业不再需要从头开始构建模型。无论是图像识别、自然语言处理还是推荐系统,都可能已经为您的用例提供了一个经过微调的模型。
神经网络通过反向传播调整权重来继续学习。在反向传播过程中,模型计算其预测误差,计算梯度以查看每个权重如何导致该误差,并更新权重以提高准确性。挑战在于使这些模型适应您的特定需求。这就是迁移学习中冻结层的作用所在。
冻结一个层意味着在人工智能训练期间,即在迁移学习期间,阻止其权重更新。冻结层允许您保留在原始模型中学习到的有用功能,同时微调需要适应此新用例的部件。
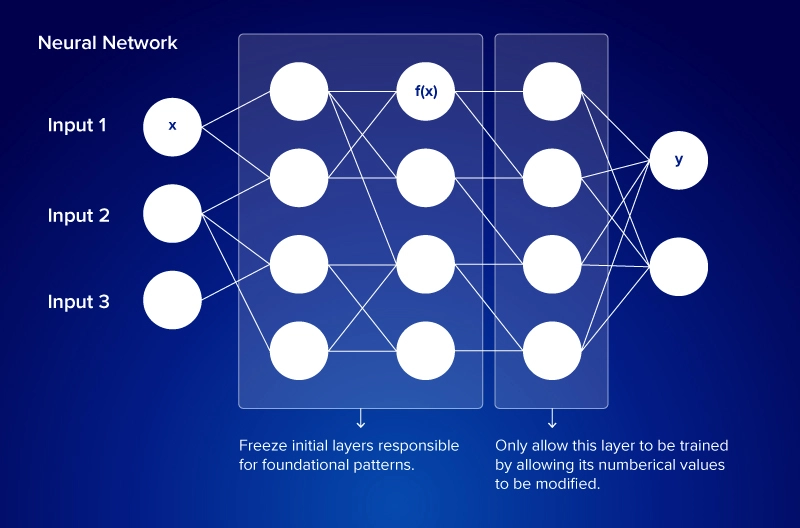
与其从头开始训练模型,不如利用迁移学习和冻结层。迁移学习是一个过程,其中为一个任务构建的教师模型被重新利用并微调为一个用于相关但不同任务的学生模型。教师模型的某些特征被冻结,而其他参数被微调和更新,从而减少训练时间,降低数据要求,并提高准确性。
当一个层被冻结时,数据仍然在正向传播中流经该层,但在反向传播中,模型会跳过该层的权重更新。
- 其权重保持固定。
- 不为其计算梯度。
- 它停止从新的训练数据中学习。
应该冻结哪些层以及何时冻结?
当你希望减少训练时间、节省计算资源并利用模型的通用特征而无需从头开始训练时,你应该冻结层。这在你的数据集较小或硬件资源有限的情况下特别有效。
例如,一家电子商务公司构建一个模型来总结客户评论,可以微调一个预训练的语言模型,如 LLaMA、BART 或 GPT。通过冻结早期层(捕获通用语言模式)并仅训练后期层(适应特定于评论的语言),团队可以节省时间同时保持准确性。
冻结层的主要优势:
- 更低的计算成本:需要更新的层更少意味着减少 GPU 和内存使用
- 更快的训练:缩短反向传播周期
- 更好的泛化:保持模型广泛的语言知识完整
在 Keras 中冻结层非常简单。下面是一个完整的示例,使用 VGG16(一个用于图像分类的 CNN),以及 Docker 设置,以便你可以在容器化环境中运行它以确保可重复性。
前言 - 回顾各层学习什么
了解神经网络中不同层学习什么对于决定在微调期间冻结哪些层至关重要。在卷积神经网络(CNN)— 通常用于图像分类 — 层遵循分层结构:
|
层类型 |
学习内容 |
视觉示例 |
|
早期(Conv1) |
边缘、梯度、简单斑点 |
垂直 / 水平线 |
|
中期(Conv2-3) |
形状、纹理、角落 |
圆形、网格 |
|
后期(Dense) |
复杂模式、对象部分 |
眼睛、面部、建筑物 |
这种知识来自:
- 梯度上升可视化:生成强烈激活神经元的输入图像,以了解它寻找什么特征。
- 激活热图:显示输入在何处以及如何强烈激活每个层
一旦你了解了结构,检查模型的实际架构以决定关键层会有帮助。要决定冻结哪些层,检查模型的架构。回顾结构有助于识别哪些块捕获低级与高级特征,使选择性冻结更有效。在 PyTorch 中,named_children () 方法列出每个层块。
for name, layer in model.named_children(): print(name)
步骤 1:创建项目文件
在你的工作目录中,创建三个文件:
- Dockerfile
- requirements.txt
- freeze_layers_example.py
Docker 文件
# Use an official Python base image
FROM python:3.10-slim
# Set working directory
WORKDIR /app
# Install system dependencies
RUN apt-get update && apt-get install -y \
build-essential \
libgl1-mesa-glx \
&& rm -rf /var/lib/apt/lists/*
# Copy requirements and install dependencies
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
# Copy training script
COPY freeze_layers_example.py ./
# Run the script
CMD ["python", "freeze_layers_example.py"]
requirements.txt
tensorflow matplotlib
freeze_layers_example.py
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Input
# Load pre-trained model without the top layer
base_model = VGG16(weights='imagenet', include_top=False, input_tensor=Input(shape=(224, 224, 3)))
# Freeze the first 10 layers
for layer in base_model.layers[:10]:
layer.trainable = False
# Add custom layers
x = Flatten()(base_model.output)
x = Dense(128, activation='relu')(x)
output = Dense(10, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Print model summary
model.summary()
步骤 2:构建并运行 Docker 容器
在终端中运行以下命令:
docker build -t freezing-layers . docker run freezing-layers
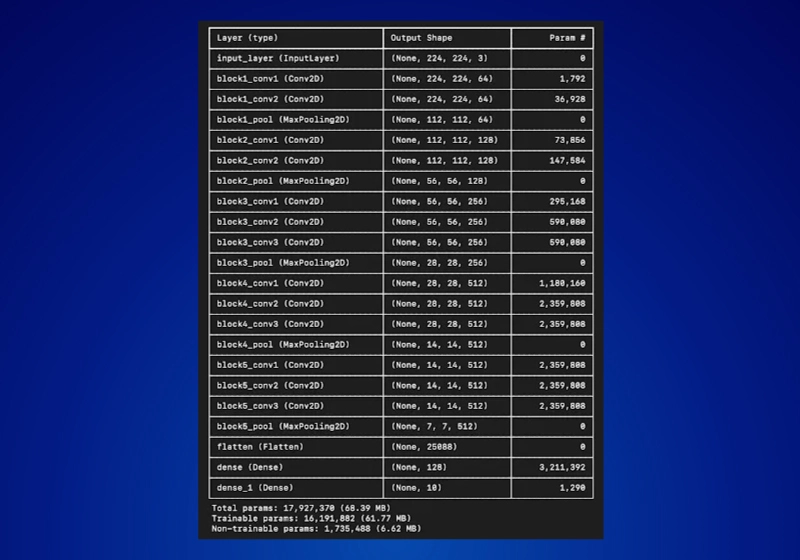
总参数:17,927,37θ(68.39 MB)
可训练参数:16,191,882 (61.77 HB)
不可训练参数:1,735,488 (6.62 MB)
从上面的示例中,我们展示了如何加载预训练模型(VGG16),冻结选定的层,并在自定义数据集上微调其余部分。这个简单的工作流程演示了迁移学习的核心原则:你不需要重新训练整个模型就能获得强大的结果。
- 冻结特定层:我们冻结了 VGG16 的前 10 个卷积层,这些层捕获了边缘和纹理等通用特征。设置layer.trainable = False可在训练期间保留这些特征。
- 添加自定义层:添加了展平层、密集隐藏层和输出分类层。这些保持可训练状态,使模型适应新的数据集。
- 重新编译模型:修改架构后,重新编译确保优化器在训练期间仅更新未冻结的层。
冻结层的常见陷阱
冻结层可以加快微调速度,但应用方式上的错误可能会损害模型准确性。以下是需要避免的最常见陷阱:
- 冻结过多层 – 锁定网络的大部分,特别是高层,会阻止对新任务的适应。这通常会导致欠拟合。
- 在小数据集上冻结过少层 – 在有限数据的情况下让大多数层保持可训练会导致过拟合,模型记住训练示例但在新输入上表现不佳。
- 选择错误的层 – 冻结特定于任务的层会降低可迁移性。始终区分通用特征(边缘、形状)和特定于任务的特征(对象部分、领域特定模式)。
- 与预训练模型的输入不匹配 – 像 VGG16 或 ResNet 这样的预训练模型需要特定的预处理(例如,归一化或 preprocess_input)。跳过这一步会导致特征对齐不良和结果不佳。
- 首先冻结早期层 – 它们捕获的通用特征(边缘、纹理)可以很好地跨任务迁移。
- 必要时逐步解冻 – 如果准确性停滞,逐步解冻中间或更高层,让模型适应。
- 匹配预处理与预训练模型 – 使用与模型原始训练期间相同的归一化、标记化或图像预处理。
- 尝试部分冻结 – 在 CNN 中,尝试冻结早期卷积块但微调密集层。在 Transformer 中,冻结嵌入和较低块,微调较高块。
- 监控验证性能 – 在调整冻结层时观察过拟合或欠拟合情况。
冻结层是迁移学习中最实用的技术之一。通过重用预训练模型学习的强大特征并仅微调重要的层,你可以节省训练时间,降低计算成本,同时仍然实现高精度。
无论你是使用 CNN 进行图像分类还是 Transformer 模型进行语言处理,冻结层的过程如下:
- 冻结捕获通用模式的层。
- 微调适应特定任务的层。
- 监控结果并根据需要通过解冻更深层进行调整。




相关贴子
-
 人工智能与大模型
人工智能与大模型W5232 G3V4 智能工作站:助力企业突破算力瓶颈,实现降本增效
2025.07.18 30分钟阅读 -
 人工智能与大模型
人工智能与大模型LLMs 的历史与未来
2024.09.20 46分钟阅读 -
 人工智能与大模型
人工智能与大模型GPU如何为设计师和工程师打开人工智能之门
2023.05.04 29分钟阅读