
博客
扩充 KV 缓存为何成为 AI 推理成功的核心关键

键值缓存(KV 缓存)已然成为搭建具备深度推理能力、支持超大上下文窗口 AI 系统的核心支柱,这类能力也是落地实际业务场景的刚需。英伟达于今年 1 月正式推出上下文内存存储架构(CMX),旨在打破行业公认的显存墙瓶颈,该架构将于今年下半年逐步部署至各行业客户数据中心。与此同时,从算力栈多层级维度优化扩容、充分释放 KV 缓存效能,仍存在广阔的技术创新空间。
在 AI 推理任务中,KV 缓存承担短时记忆职能,是保障 AI 推理服务流畅稳定运行的核心,尤其适配依托超大上下文窗口开展 AI 推理计算的业务场景。其核心原理为预存智能体高频问答的计算结果,再次接收同类请求时可直接调取复用,大幅缩短响应耗时。
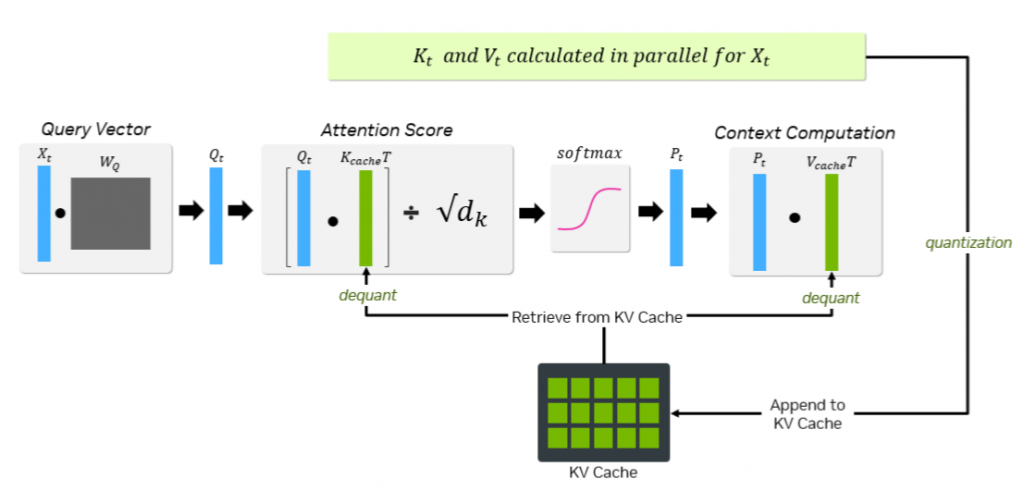
模型预填充阶段生成的计算结果会存入 KV 缓存,供后续推理调用(图源英伟达官方博文:《基于 NVFP4 键值缓存优化长上下文与大批量推理任务》)
从技术原理来讲,KV 缓存主要存储 AI 推理预填充阶段(读取阶段) 的运算数据,该阶段高度依赖 GPU 与 AI 加速芯片算力。AI 输入数据完成各注意力层状态计算后,推理进入解码生成阶段(输出阶段),逐词输出应答内容。借助 KV 缓存留存高频注意力键值数据,可避免 GPU 重复运算,有效提升文本生成速度、降低用户侧推理延迟。
理想状态下,全部 KV 缓存数据都存储在 GPU 近邻的高带宽内存(HBM)中,最大限度缩短数据传输路径,兼顾低延迟与高吞吐性能。但受硬件规格限制,现有 HBM 容量既无法承载业务所需的超大上下文数据,也难以同时兼顾模型运行所需的各类内存调度任务。
DDN 公司产品高级副总裁 James・Coomer 指出:神经网络权重通常会占用约 30% 的 HBM 空间,各类临时运算数据再占用 30%,最终仅剩余 30% 空间可用于存放 KV 缓存,实际业务中很快就会出现容量耗尽问题。
行业主流解决思路是将溢出的 KV 缓存数据分流至其他内存与存储介质,优先存入系统内存 DRAM;当内存资源占满后,再分流至高速存储设备,优选搭载高速网络架构的 NVMe 固态存储。固态存储虽性能优异,但读写速度依旧远不及 HBM,势必会增加整体推理延迟,而在当前 AI 算力需求与硬件技术条件下,这也是现阶段最可行的落地方案。
英伟达 CMX 架构正是为解决该痛点而生,主打实现 KV 缓存数据向外部存储设备高效分流。这套 1 月发布的架构方案面向存储生态合作伙伴开放,依托蓝域 4 号数据处理器(BlueField-4 DPU),借助 RDMA 高速互联技术,打通英伟达维拉・鲁宾全栈推理算力平台(整合鲁宾 GPU、维拉 CPU、格罗克 LPU)与 DDN 等厂商高速存储集群之间的数据传输链路。

英伟达 CMX 平台全面搭载 BlueField-4 DPU 硬件
目前 CMX 架构仍处于持续迭代研发阶段,DDN 及一众存储厂商正基于这套通用技术蓝图打造定制化解决方案,各家产品差异化布局将在 2026 年下半年逐步落地。
现阶段各大企业仍在搭建 AI 推理业务集群,行业亟需厘清 KV 缓存的核心价值,以及各类架构设计对缓存调度效率带来的实际影响。Coomer 表示:“KV 缓存优化至关重要,我们投入大量精力梳理行业通用标准,精准研判客户实际业务中缓存加速带来的真实使用体验。”
诸多因素都会直接影响 KV 缓存运行效率与终端使用体验,高速网络链路、高性能存储介质是基础保障,并行文件系统、适配 CMX 架构与 KV 缓存集群的 S3 对象存储加速技术,同样起到关键赋能作用。
除此之外,部署规划中的多项核心要素,也直接决定 KV 缓存的实际使用效果:
- 并发承载规模:可支撑十几人、百人级并发与千人、万人级 AI 服务并发,在缓存调度逻辑与资源配比上存在天壤之别;
- 上下文窗口规格:普通业务仅需少量文本上下文,科研、工程类复杂场景则需要十万词及以上超长上下文完成逻辑推演;
- 会话持久时长:部分场景仅需单日短期会话留存,工业级、科研级业务则要求会话状态连续稳定数周甚至数月;
- 延迟性能指标:部分离线业务可容忍分钟级响应时延,实时交互类 AI 服务一旦响应超时 10 秒,便会彻底丧失商用价值。
全新 AI 推理服务上线初期,KV 缓存处于空白状态,所有用户请求都需要 GPU/AI 加速芯片从零完成注意力键值运算。随着业务持续运行、用户请求不断累积,缓存数据体量逐步扩容,缓存未命中概率持续下降。据 DDN 实测客户数据显示,成熟业务场景下缓存命中率可达 85%。
物理内存(HBM/DRAM)与后端存储的容量配比,是分布式 KV 缓存体系性能的决定性因素。Coomer 提出行业通用配比思路:后端存储总容量可达到物理内存容量的一千倍。以搭载约 13TB HBM 显存的英伟达 NVL72 集群为例,配套后端存储集群规划容量可达到 13PB,最终配比仍需结合业务场景综合调整。
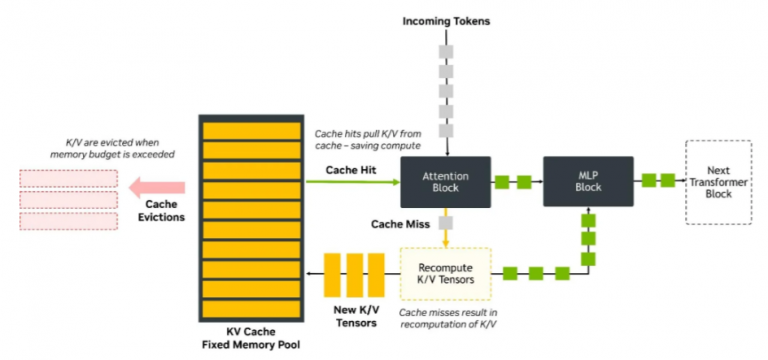
缓存命中可直接复用历史键值张量数据,大幅降低 GPU 算力负载;缓存未命中则需要重新完成键值运算,拉高硬件算力占用率(图源英伟达官方博文:《基于 NVFP4 键值缓存优化长上下文与大批量推理任务》)
数据压缩技术同样是优化 KV 缓存的重要手段。谷歌近期发布全新 TurboQuant 量化压缩算法,可大幅提升向量量化压缩效率,有效缩减 KV 缓存与向量数据库的内存、存储空间占用。
同时,算力芯片型号、大模型架构、推理框架、推理引擎等全栈软硬件体系,都会间接影响 KV 缓存调度效率。英伟达 CMX 架构深度适配自家全系软硬件生态,谷歌则针对云环境 Lustre 文件系统,自研专属 KV 缓存溢出调度方案。
根据英伟达 3 月公开技术文档,CMX 架构由多款核心组件协同搭建:开源分布式推理框架 Dynamo、智能路由组件 DOCA Memos,以及专为 AI 推理点对点高速数据传输打造的开源库 NIXL。官方介绍中明确:DOCA Memos 部署于 BlueField-4 之上,负责实现缓存感知调度与 IO 读写管控;Dynamo 与 NIXL 则完成上下文数据排布、缓存复用能力与推理服务层的深度融合。
目前 DDN 联合 Vast Data、WEKA、Everpure(前身为 Pure Storage)、NetApp 等主流存储厂商,共同研发适配英伟达 STX 机柜标准的 CMX 生态解决方案,行业入局热潮正式开启。
Coomer 评价道:“英伟达正在搭建一套规范统一、清晰完善的行业技术标准,为产业落地筑牢根基。当前整个赛道尚处于野蛮生长阶段,各家企业都在摸索技术路线、打磨适配方案,多数厂商暂未对外公开核心布局,但全行业都在全力攻坚 KV 缓存集群搭建技术。”
深耕 AI 领域多年的 Coomer,十分看好行业发展前景,但也直言当前大模型依旧存在明显短板,最突出的便是上下文中段信息遗忘问题—— 模型能够清晰记住对话首尾内容,却极易丢失中间关键信息。
他表示:“如今 AI 能力进步有目共睹,但日常使用中依旧容易受限于注意力机制缺陷,面对超长上下文问答场景,无法兼顾全部有效信息。攻克注意力机制瓶颈、扩充模型上下文感知范围,是当下最核心的突破方向。”
全球范围内千亿级资金持续涌入超大规模数据中心建设,海量 GPU、TPU 算力集群、海量高带宽内存资源,搭配全品类行业业务数据全面落地。放眼行业,看似不起眼的 KV 缓存扩容优化,或许正是彻底释放 AI 全部潜能的关键密钥。
对此 Coomer 笃定:“谁率先攻克 KV 缓存与长上下文调度难题,谁就能牢牢掌握未来 AI 产业发展的主动权。”



相关贴子
-
 人工智能与大模型
人工智能与大模型人工智能自动化如何提高科研生产力
2025.02.26 20分钟阅读 -
 人工智能与大模型
人工智能与大模型联泰集群 W7系列 液冷工作站:AI 训练不卡壳、模型出得快,这才是 AI 团队该有的算力神器
2025.12.26 13分钟阅读 -
 人工智能与大模型
人工智能与大模型什么是多层感知以及何时使用 MLP 与 Transformers
2025.06.20 48分钟阅读