
博客
SXM 与 PCIe:最适合训练 LLM 的 GPU,如 GPT-4
什么是 NLP,什么是 LLM?
自然语言处理(NLP)是人工智能(AI)的一个分支,使机器能够理解和解释人类语言。深度学习的最新进展导致了大型语言模型(LLM)的出现,它显示了不可思议的自然语言理解能力,彻底改变了世界,对未来产生了重大影响。初创企业和公司已经选择在 NVIDIA 的专用硬件上训练这些 LLMs:DGX。
大型语言模型(LLM)是一种语言模型,由在大量无标签文本数据上训练的参数神经网络组成。最著名的 LLM 是 OpenAI 的 GPT(Generative Pre-trained Transformer)系列,它已经在数十亿字的基础上进行了训练,是 ChatGPT 的基础。各种应用以 GPT 为基础,建立了极具说服力的聊天机器人、总结器等。LLM 在广泛的 NLP 任务中表现出卓越的性能,如语言翻译、问题回答和文本生成。ChatGPT(最初在 GPT-3 上训练)和 ChatGPT Plus(在 GPT-4 上训练)在将人工智能带到公众和消费者的关注点上掀起了巨大的波澜。
使我们的计算机能够与我们的物理世界互动已经成为现实。LLMs 在各个行业都有大量的应用,如个性化的聊天机器人、客户服务自动化、情感分析和内容创作,甚至是代码。那么,为什么这些大型组织会选择 NVIDIA DGX?DGX 和传统的 PCIe GPU 之间有什么区别?
NVIDIA DGX/HGX 和 SXM GPU 外形尺寸
SXM 架构是一种高带宽插座式解决方案,用于将 NVIDIA Tensor Core 加速器连接到其专有的 DGX 和 HGX 系统。对于每一代 NVIDIA Tensor Core GPU(P100、V100、A800 以及现在的 H800),DGX 系统 HGX 板都配有 SXM 插座类型,为其匹配的 GPU 子卡实现了高带宽、电力输送等功能。

专门的 HGX 系统板通过 NVLink 将 8 个 GPU 互连起来,实现了 GPU 之间的高带宽。NVLink 的功能使 GPU 之间的数据流动速度极快,使它们能够像单个 GPU 野兽一样运行,无需通过 PCIe 或需要与 CPU 通信来交换数据。NVIDIA DGX H800 连接了 8 个 SXM5 H800,通过 4 个 NVLink 交换芯片,每个 GPU的带宽为 400 GB/s,总双向带宽超过 3.2 TB/s。每个 H800 SXM GPU 也通过 PCI Express 连接到 CPU,因此 8 个 GPU 中的任何一个计算的数据都可以转发回 CPU。我们将在后面介绍架构原理图。
英伟达 H800 PCIe 外形尺寸
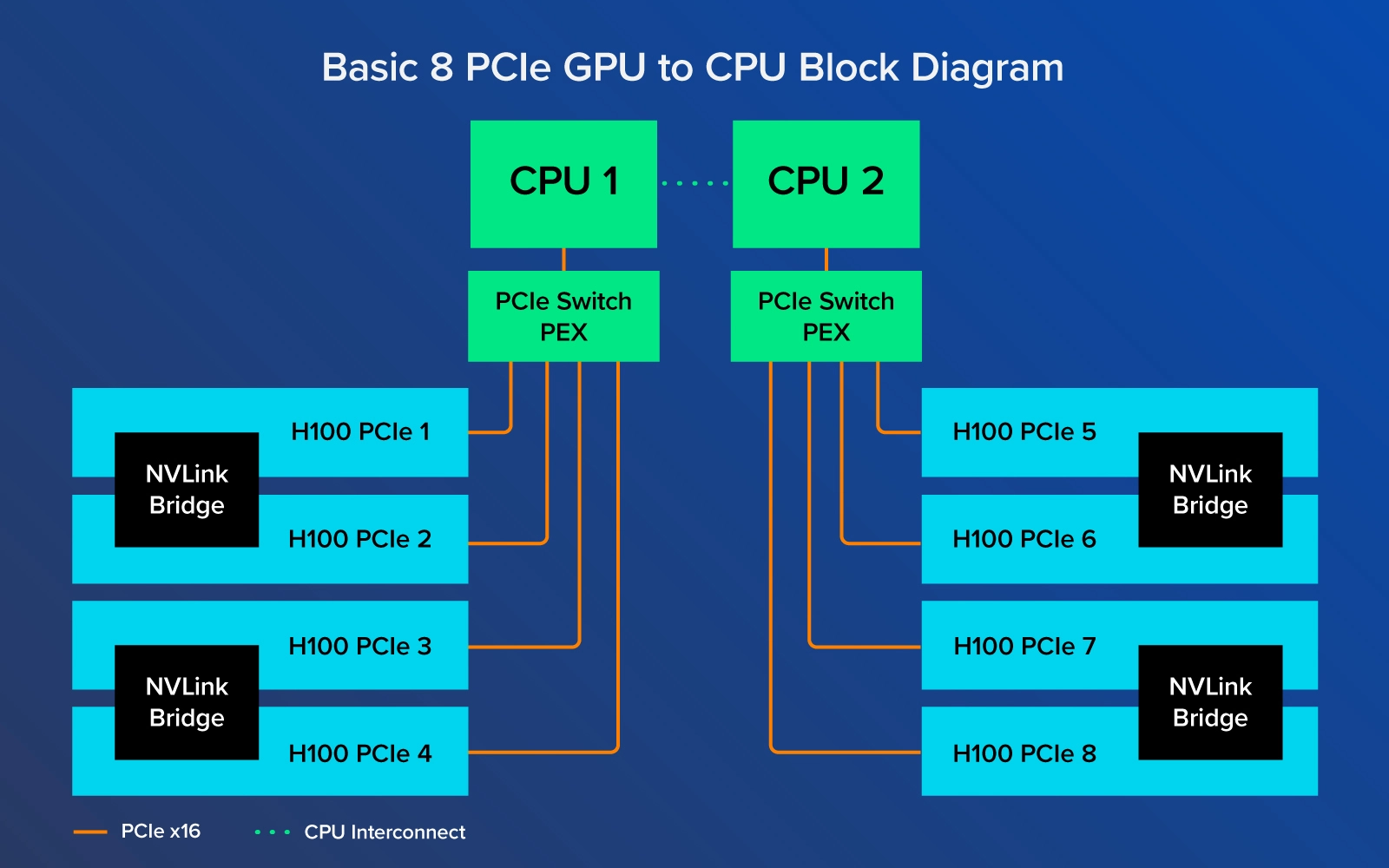
你无法通过 H800 PCIe 配备的 NVLink Bridges 与 PCIe 变体实现同样的性能带宽连接。这些桥接器只能将 GPU 成对连接在一起,实现 400GB/s 的双向传输,而不是通过系统中的 8 个 GPU 实现完整的 400GB/s。
现在不要误解,NVIDIA H800 PCIe 是一个非常有能力的 GPU,可以轻松部署。它们可以很容易地被安装到重视升级的数据中心中,只需最小的架构变化。H800 NVL 扩展了强大的 PCIe 卡,将它们搭配在一起,总共有 188GB HBM3,具有与 H800 SXM5 相当的性能。

我们的系统经过了严格的测试和验证。探索 联泰集群 Hooper H800 解决方案,包括 SXM 和 PCIe 选项!
H800 SXM 和 PCIE 的区别
众所周知,在数据中心和人工智能行业,NVIDIA DGX 简直就是黄金。它是最好的,也是最强大的 AI 机器。最突出的就是 OpenAI 在其 NVIDIA DGX 系统上训练 ChatGPT。事实上,OpenAI 早在 2016 年就拿到了第一台 NVIDIA DGX-1。
大型企业对英伟达 DGX 趋之若鹜,并不是因为它很耀眼,而是因为它的扩展能力。SXM GPU 更适合规模化部署,八 个 H800 GPU 通过 NVLink 和 NVSwitch 互连技术完全互连。在 DGX 和 HGX 中,8 个 SXM GPU 的连接方式与 PCIe 不同;每个 GPU 与 4 个 NVLink Switch 芯片相连,基本上使所有的 GPU 作为一个大 GPU 运行。这种可扩展性可以通过英伟达 NVLink Switch 系统进一步扩展,以部署和连接 256 个 DGX H800,创建一个 GPU 加速的 AI 工厂。
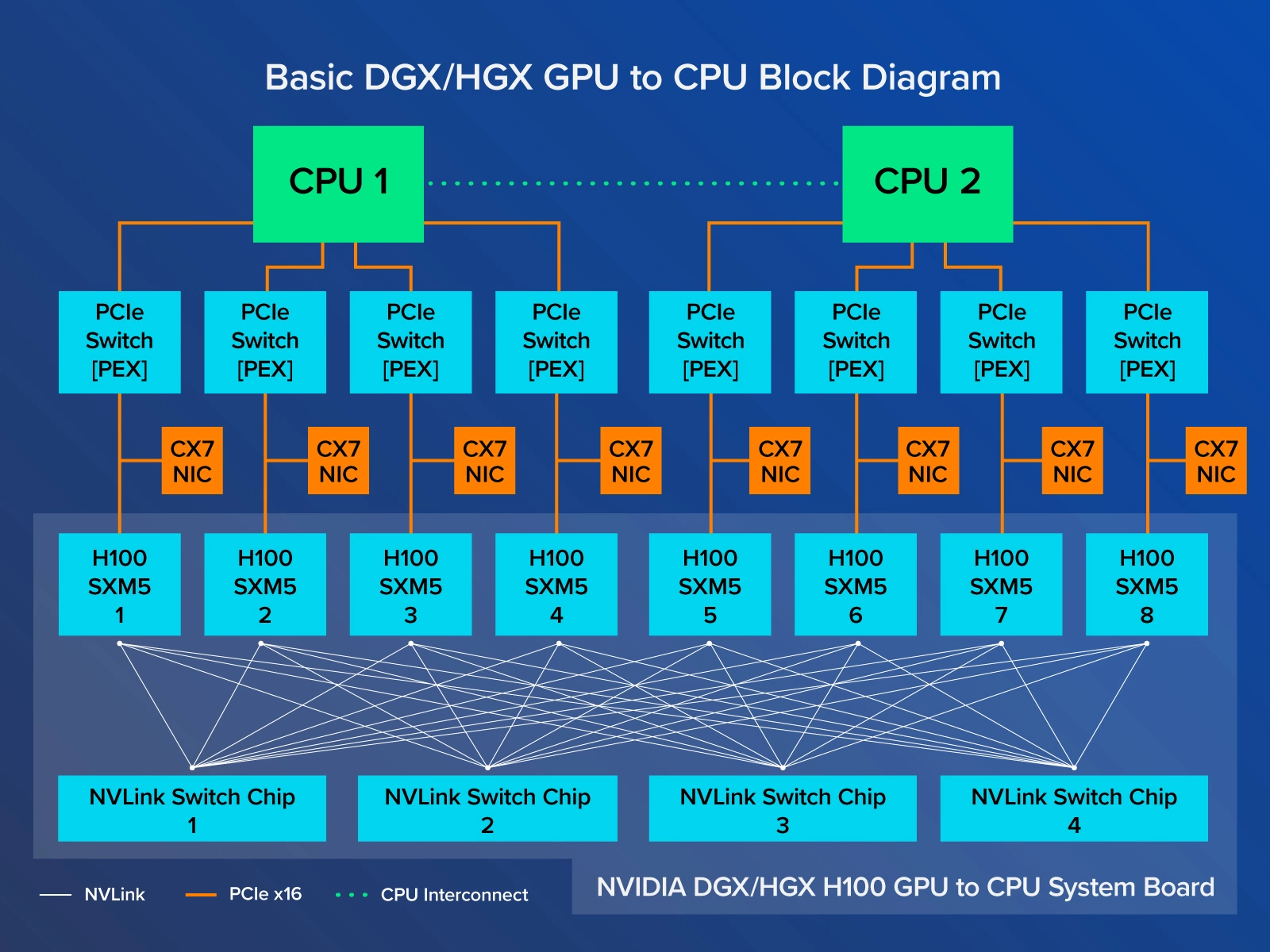
另一方面,H800 NVL 中的 H800 PCIe,只有成对的 GPU 通过 NVLink Bridge 连接。GPU 1 只直接连接到 GPU 2,GPU 3 只直接连接到 GPU 4,等等。GPU 1 和 GPU 8 没有直接连接,因此只能通过 PCIe 通道进行数据通信,不得不利用 CPU 资源。英伟达 DGX 和 HGX 系统板上的所有 SXM GPU 都通过 NVLink Switch 芯片互联,因此在 GPU 之间交换数据时不会因为 PCIe 总线的限制而减慢速度。向 CPU 发送数据仍将通过 PCIe 通道进行。
通过在 GPU 之间交换数据时绕过 PCI Express 通道,速度极快的 SXM H800 GPU 可以实现最大的吞吐量,而且比其 PCIe 同行的速度更慢,非常适合用于训练有海量数据的极大型AI模型。电力的消耗和专有的外形尺寸是对峰值性能的权衡,可以延长训练和推理时间。但是,当涉及到开发大型语言模型,对使用你的服务的数百万人进行文本推断时,需要最高形式的计算,以确保稳定性、流畅性和可靠性。
你应该选择什么?H800 SXM 还是 H800 PCIe?
这要看你的用例了。大型语言模型和生成性人工智能需要非常高的性能。但是,用户数量、工作负荷和训练规模在挑选合适的系统方面起着很大作用。
英伟达 H800 的 DGX 和 HGX 最适合那些能够利用原始计算性能的组织,不会让任何东西浪费掉。在发挥其最大潜力的情况下,不断的训练、推理和操作可以迅速降低总拥有成本。
NVIDIA DGX 具有最佳的可扩展性,所提供的性能是任何其他服务器在其给定的外形尺寸中无法比拟的。将多个 NVIDIA DGX H800 与 NVSwitch 系统连接起来,可以将多个 DGX H800 扩展为 SuperPod,以实现极大型模型。NVIDIA DGX H800 的外形尺寸为 8U,配备双英特尔至强8480C,共 112 个CPU核心。NVIDIA DGX 是不可定制的,是全面人工智能计算基础设施的构建模块。有了 NVIDIA DGX,在训练 LLM 时可以轻松地进行扩展。更多的 DGX 相当于更快的训练和更强大的部署。
英伟达 HGX 在单一系统中提供了强大的 GPU 性能,为用户提供了定制的选择。HGX 平台是由特定的合作伙伴(如 联泰集群)提供的可定制平台,可提供客户所需的性能-- CPU、内存、存储、网络--同时仍然利用相同的 8x NVIDIA H800 SXM5 系统板(包括所有 NVLink 的好处)。这些系统可以满足数据中心的需求,可以选择自己的网卡、自己想要的 CPU 核心数量,有时还可以选择额外的存储。英伟达 HGX 在计算能力方面与 DGX 类似,同时还能满足大规模 LLM 训练的需要。
英伟达 H800 PCIe 变体适用于那些工作负荷较小、希望在决定系统中的 GPU 数量方面获得最大灵活性的用户。在性能方面,这些 GPU 仍然很强大。它的原始性能数字略低,但由于易于安装到任何计算基础设施中,因此这些 GPU 非常引人注目。H800 PCIe 还提供较小的外形尺寸,如 1U 和 2U,供数据中心在单 CPU 或双 CPU 配置中使用 2x 或 4x GPU,为小型 LLM 开发提供计算能力。更多的 1 :1 的 CPU 与 GPU 比例有利于在推理中部署更多的虚拟化功能,以及分析等一系列不同的应用。





相关贴子
-
 技术分享
技术分享这台服务器正在悄悄改变中国 AI 产业格局!
2025.07.04 33分钟阅读 -
 技术分享
技术分享Ollama 与 vLLM 深度对比:大模型部署方案如何选型
2026.05.18 70分钟阅读 -
 技术分享
技术分享Ansys HPC Pack——解读 CPU 和 GPU 的 Ansys 许可
2024.08.02 83分钟阅读