
博客
HPC
让 AI 训练不再「排队」!集群扩容,70 个科研任务并行无忧
2025.03.21
35分钟阅读

-
异构计算节点 1:2 台双路 Intel 4316 8 GPU 卡服务器(Ada Lovelace 架构 24GB); -
异构计算节点 2:2 台双路 Intel 4316 8 GPU 卡服务器(Ada Lovelace 架构 48GB);
-
存储节点:3 台双路 36 盘位存储服务器(352TB*3);
-
网络部分:机房改造;
-
集群管理:LtAI 异构资源管理平台,搭建统一 AI 计算资源池;
-
支持资源调度、监控、管理;
-
支持组织、用户管理;
-
支持存储管理;
-
支持数据标注;
-
支持数据管理;
-
支持模型训练、模型管理、模型服务;
-
支持开发环境管理,各种 AI 框架;
-
支持 AutoML 超参调优;
-
存储管理:LTHPC 并行存储系统,搭建高性能存储资源池;
-
支持副本/纠删码技术特性; -
支持在线横向扩展,容量可达 EB 级; -
支持 NFS/SMB/POSIX 等协议,无性能瓶颈; -
多级可靠性保障,保证业务连续性和安全性;; -
支持非结构化数据之间协议融合互通访问,基于 ROW 的可以快照功能等;
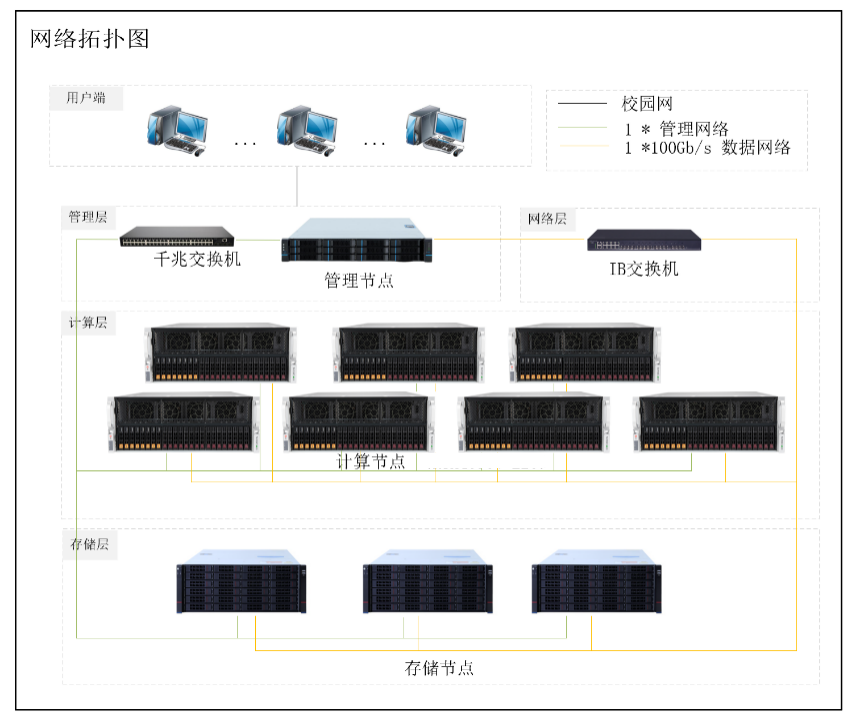
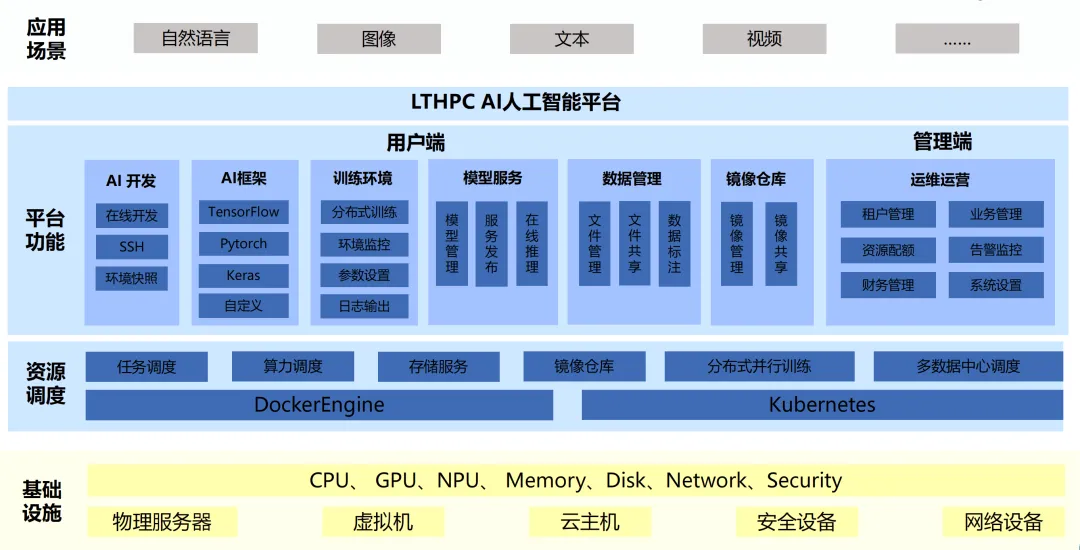
-
AI 集群整体单精度算力 3558.4 TFLOPS,GPU 总显存 2112GB; -
存储裸容量 1PB,可用容量高达 600TB; -
新增设备无缝加入原集群,用户业务不中断; -
分布式存储支持 RDMA、GDS 等技术,对前端 GPU 服务器的增速巨大,超额完成训练任务; -
纠删码/副本的部署方式,一定程度上保证了用户的数据安全。





相关贴子
-
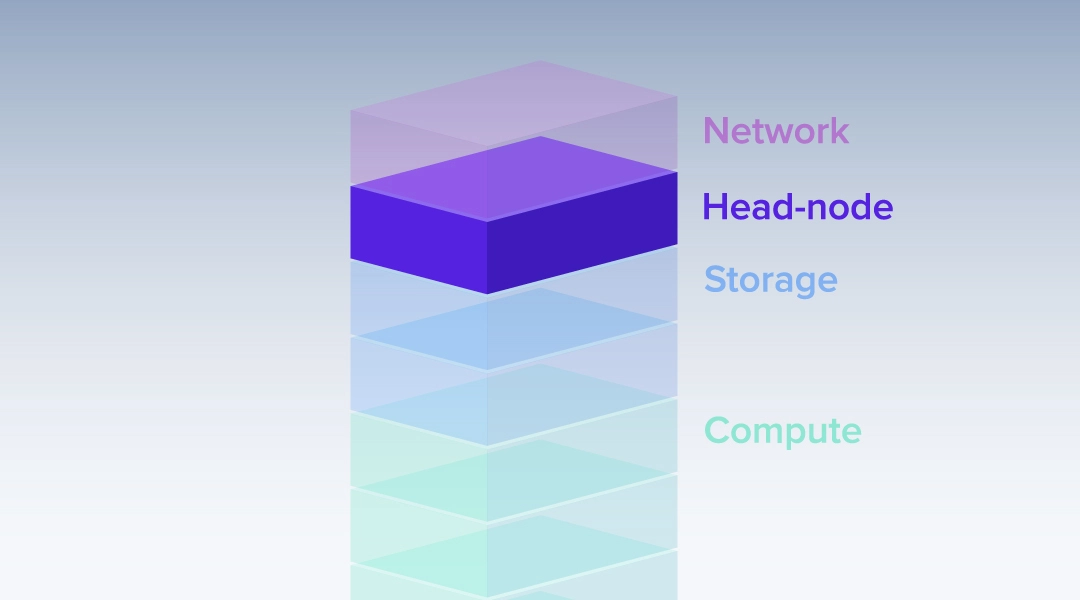 HPC
HPC集群拓扑结构:什么是头节点?
2024.01.12 42分钟阅读 -
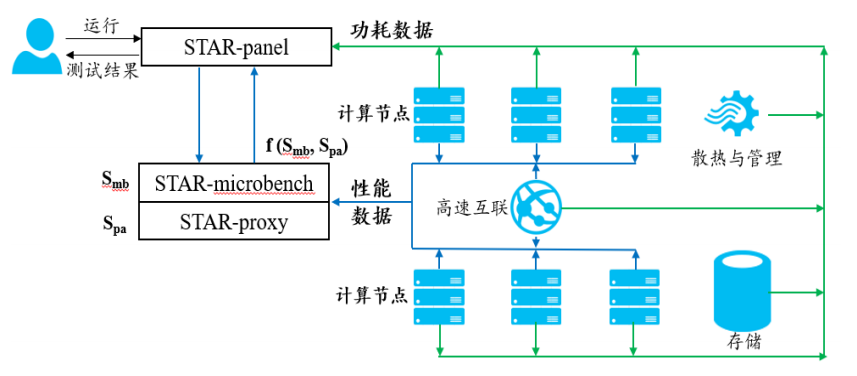 HPC
HPC收藏:应用场景高性能测试方法(高性能计算)
2023.01.12 98分钟阅读 -
 HPC
HPC联泰集群国产服务器GK2238——基于鲲鹏920处理器的国产AI服务器
2023.01.12 10分钟阅读