
博客
联泰集群赋能四川某科大计算机学院 AI 科研平台,打造高性能 GPU 算力集群!

四川某科技大学计算机学院在人工智能与深度学习、医学影像技术等前沿领域成果斐然,广泛应用于政府、医疗等多个行业。随着科研团队的壮大和需求的增长,学院急需提升 GPU 算力。为此,我们携手共建高性能、高扩展的人工智能科研平台,为学院师生团队插上 AI 科研的翅膀!
本次集群建设旨在满足 30 个以上用户的日常科研训练需求,采用高性能 CPU 和 GPU 服务器构建异构计算平台,专注于图像训练和自然语言处理训练。集群整体 GPU 算力不低于 1PFLOPS,显存容量高达 900GB,确保科研任务的高效运行。同时,集群网络采用高速链路,并保留扩展性,为后续无缝加入计算节点和存储节点打下坚实基础。
学院现有的通用服务器已无法满足 AI 科研任务的需求,GPU 算力资源紧缺。AI 开发流程及环境部署复杂,缺乏完整的科研平台。服务器使用管理混乱,急需采购集群管理软件进行统一分配管理。此外,学院机房条件还需进行电力改造,以满足大功耗 GPU 服务器的加入。
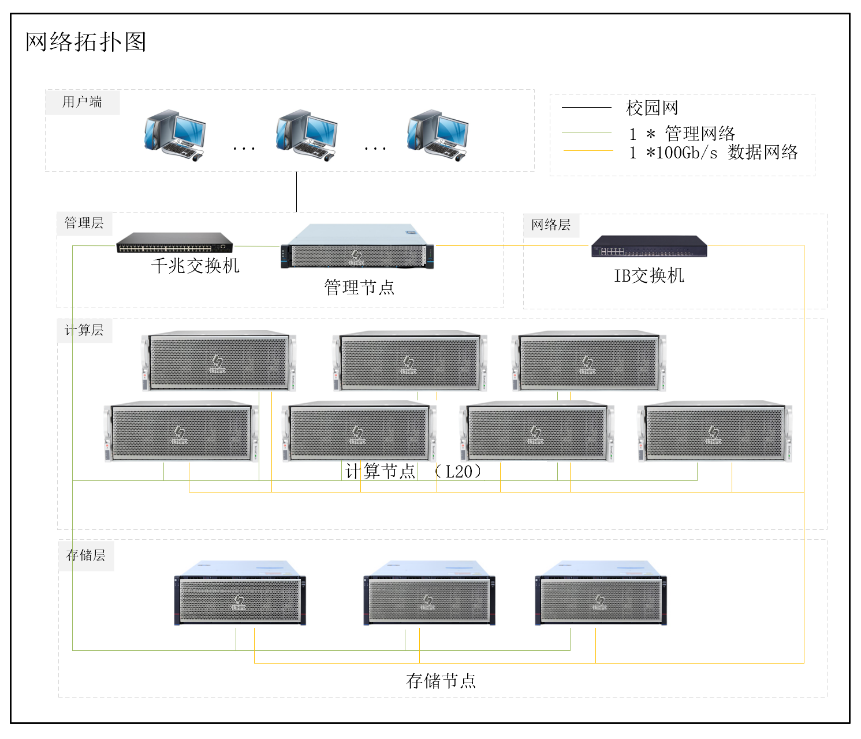
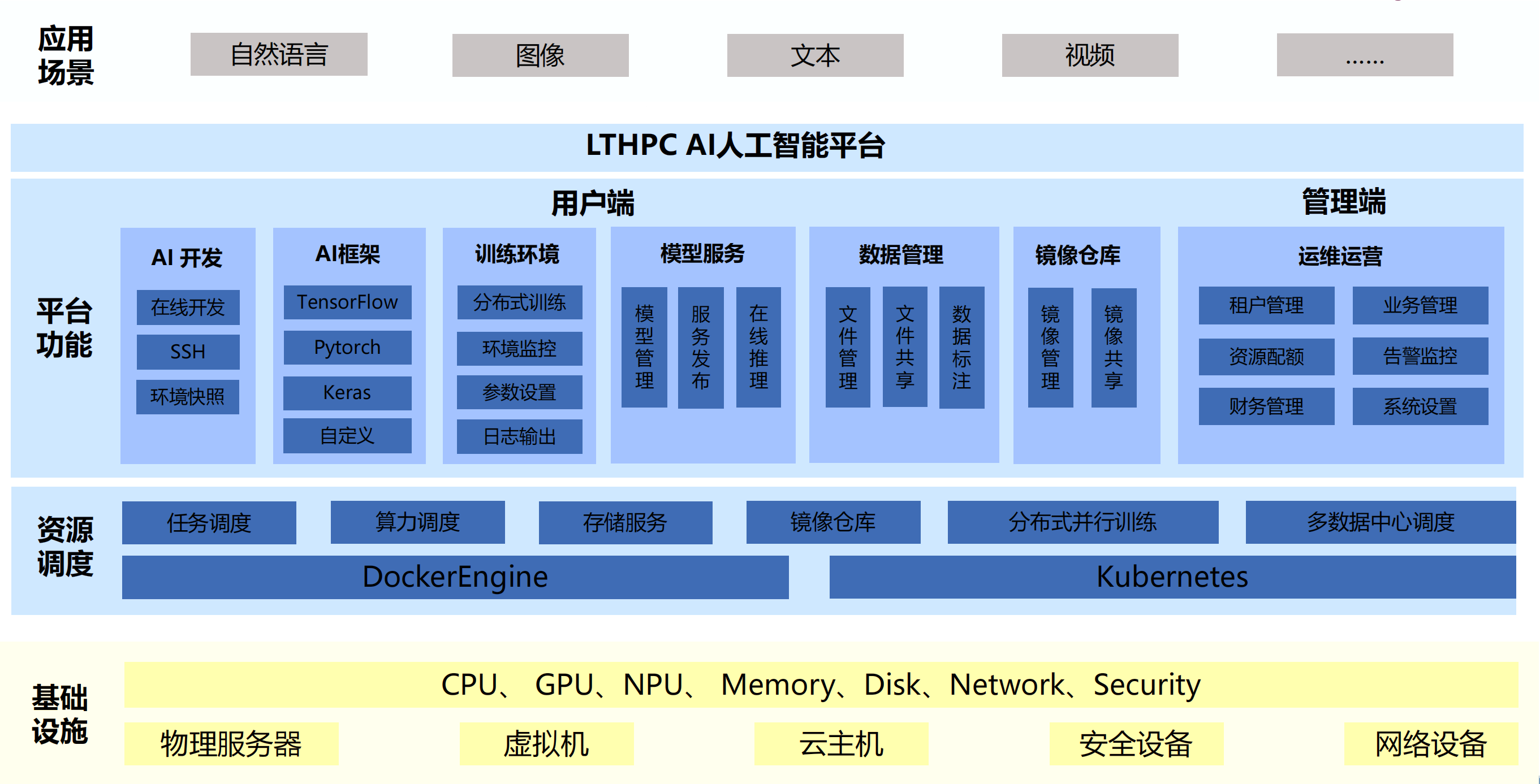
针对学院痛点,我们采用 GPU 加速的 Kubernetes 集群架构,提供简洁的 WEB 界面和丰富的功能工具。该方案支持资源调度管理、用户管理、模型训练、数据标注等多样化技术特性,为用户提供充足的异构计算资源和开箱即用的开发环境。具体硬件平台架构包括:
-
管理节点:1 台双路 Intel® Xeon CPU 4310 管理服务器
-
计算节点:3 台双路Intel® 4316 8 GPU 服务器(L20 48GB)
-
网络部分:千兆交换机和 100GbE IB 交换机各 1 台
-
集群管理:LtAI 异构资源管理平台,实现资源的统一调度、监控和管理
(点击放大查看)
(点击放大查看)
经过半年的试运行,该校 AI 集群系统赢得了用户的高度赞赏。具体收益包括:
-
CPU 核心数高达 144,GPU AI 算力可达 1280 TFlops
-
资源统一管理与调度,提升资源利用率
-
全流程 AI 开发与管理,降低 AI 开发复杂度
-
无缝拓展集群节点,为二期建设降低门槛
此次 AI 科研平台的升级不仅提升了学院的科研实力,也为师生团队提供了更加便捷、高效的 AI 研究环境。



相关贴子
-
 人工智能与大模型
人工智能与大模型LtONE 智能体应用平台:构建大模型驱动的自主行动生态
2026.04.03 32分钟阅读 -
 人工智能与大模型
人工智能与大模型赋能 AI 大模型训练推理助力 DeepSeek 落地-LTHPC G6228 G3
2025.02.26 34分钟阅读 -
 人工智能与大模型
人工智能与大模型人工智能自动化如何提高科研生产力
2025.02.26 20分钟阅读