
博客
GPU 加速流体和粒子模拟-使用 Enginsoft 进行 Particleworks 基准测试

基于粒子的模拟通过实现流体动力学的精确建模,彻底改变了工程和设计。Particleworks 是一款领先的计算流体动力学(CFD)仿真软件,利用高性能计算硬件,特别是 GPU,实现卓越的性能。
Particleworks 采用无网格运动粒子模拟(Moving Particle Simulation,MPS)方法来解决复杂的流体动力学问题,如多相流、大变形、共轭传热以及流体与运动部件的相互作用。它的应用涵盖了不同的行业,包括汽车、土木工程、制造业等。
EnginSoft 提供了行业专业知识来进行模拟,探索 GPU 如何在 Particleworks 仿真中超越 CPU,从而显著提高性能并塑造工程仿真的未来。
为了衡量 GPU 加速的影响,我们使用 Particleworks 模拟进行了一个基准测试,基线是一个强大的 128 核 CPU。我们测试了各种 GPU 的相对加速性能。
图1: GPU 相对于 CPU 的单精度加速(FP32)
此图突出显示了将 GPU 性能与 128 核 CPU 基线进行单精度(FP32)模拟时实现的相对加速。FP32 计算适用于峰值精度对整体模拟结果不重要的场景。
-
NV 几何力 光追 4XYX 的 CPU 速度提升了 11.26 倍,而 NV 光追 6XXX Ada 的 CPU 速度则提升了 9.34 倍。对于单 GPU 设置,光追 4XYX 提供了卓越的性能,在这种情况下超过了 NV 光追 6XXX Ada,但还有其他因素需要考虑:
-
光追 4XYX 具有更高的时钟速度,但仅限于 24GB 的 GPU 内存,因此不太适合大规模模拟。此外,较大的冷却器尺寸限制了您可以在单个系统中部署的 GPU 数量。
-
光追 6XXX Ada 与 光追 4XYX 共享相同的 GPU 架构,但时钟速度较低。光追 6XXX Ada 的优势在于其 48GB 的 GPU 内存和专业应用程序验证,可增强稳定性。它非常适合可扩展的 GPU 计算任务,可以部署在多 GPU 设置中,例如工作站中最多 4 个 GPU 或服务器中最多 8 个 GPU。
-
像 NV H1XX 这样的高端专业 GPU 可能无法在单精度工作负载中充分发挥其潜力,因为光追 4XYX 和光追 6XXX Ada 等 GPU 受益于更高的时钟速度。这并不是说 7.71x 的加速无论如何都很慢。然而,如图 2 所示,H1XX 在双精度(FP64)计算方面表现出色,而其他 GPU 则不然。
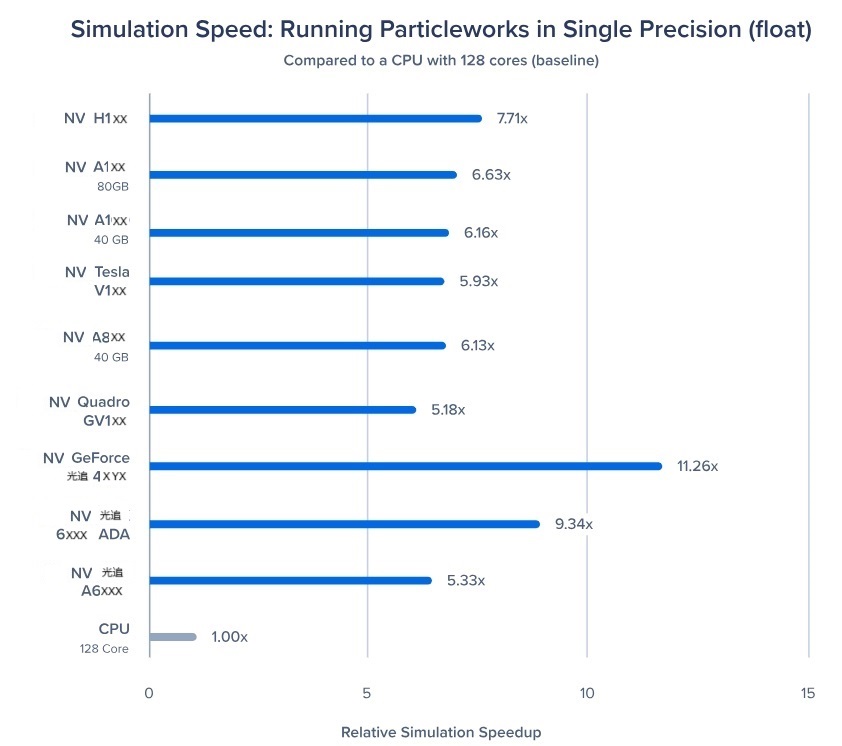
图 1
最佳选项:光追 4XYX、光追 6XXX Ada、光追 A6XXX 和其他专业光追 或 几何力 光追 GPU。
-
专业 光追 GPU:提供专用驱动程序和专业级支持,以提高稳定性和可靠性。这些 GPU 针对可扩展性进行了优化,在全塔工作站中最多支持 4 个 GPU,并提供了服务器部署的灵活性。
-
几何力 光追 GPU:这些显卡主要用于游戏,可为单精度工作负载提供出色的性能,但缺乏同等水平的专业支持。它们较大的插槽宽度会限制可扩展性,通常会将工作站限制在 1 个或 2 个 GPU 上,如光追 4XYX,而且通常不适合服务器内部。
图2:双精度 FP64 中 GPU 相对于 CPU 的加速
第二张图展示了运行模拟时的相对加速,就像图 1 一样,但采用 FP64 双精度。双精度计算是使用峰值精度模拟计算的首选方法。
-
图1:由于非原生 FP64 功能,表现最好的程序在这里的表现却不佳。然而,使用 NV H1XX 和 NV A1XX,我们可以分别看到 7.33 倍和 6.02 倍的加速。
-
NV H1XX 和 A1XX 都是带有被动冷却器的数据中心级 GPU,需要部署服务器。这些 GPU 不能在台式机/工作站部署中使用。
-
NV H1XX 和 A1XX 具有 80GB 的 HBM 内存,可提供极快的内存带宽和高内存大小,非常适合较大型号。当 NVLinked 在一起时,这些 GPU 可以更好地协同工作。
-
NV A8XX 40GB Active 是基于 NV A1XX 的工作站级卡。NV A8XX 具有 5.52 倍的加速。
-
由于 A8XX 是类似于光追 6XXX Ada 的鼓风机式显卡,因此这些 GPU 可以安装在工作站中。
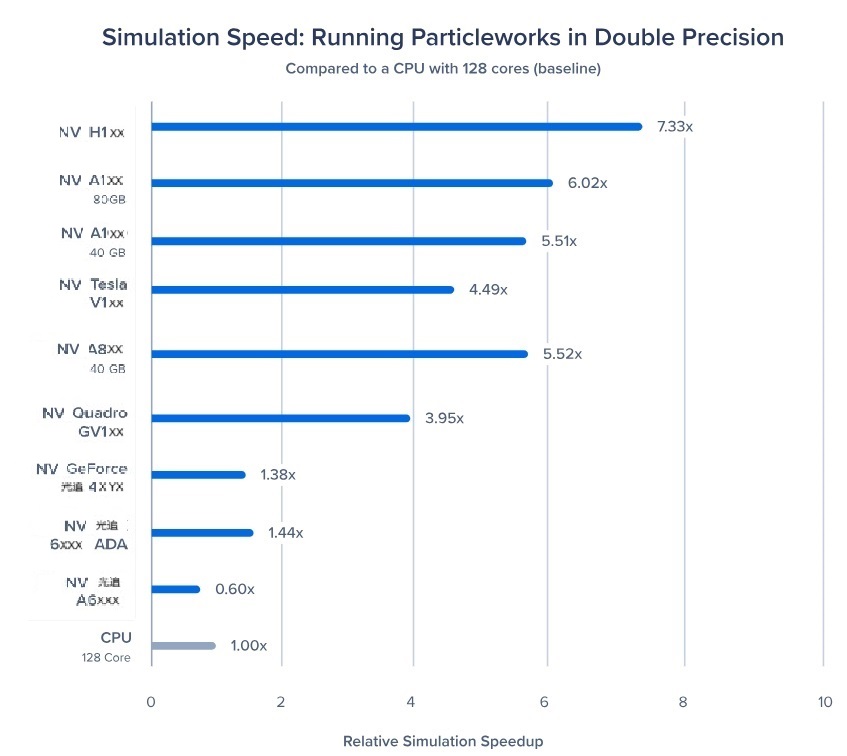
图 2
最佳选择:企业级的 GPU,如 NV H1XX 和 NV A1XX Tensor Core GPU。最近发布的 NV H2XX NVL 具有 141GB 内存(未经测试),可以提供更高的性能。
-
这些 GPU 专为服务器部署而设计,使其成为共享 HPC 计算环境的理想选择。
-
NV A8XX 的灵活性:虽然从技术上讲,A8XX 40GB Active 是工作站级 GPU,但它在工作站外形上提供了企业级性能。这使得它成为在较小系统中需要双精度功能的用户的多功能选择。
图 3 和图 4: Particleworks 多 GPU 可扩展性
我们还测试了部署多 GPU 设置时的可扩展性,以确认使用额外的 GPU 是否可以提高性能。2 个 GPU 的性能会翻倍吗?4x GPU 的性能是四倍吗?
我们还在单精度(浮点)和双精度上测试了这一点,1x GPU 是基准性能。
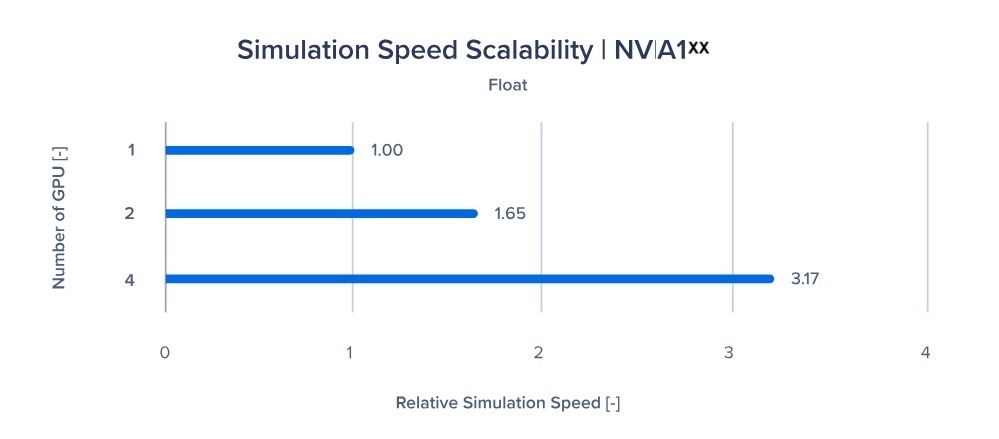
图 3
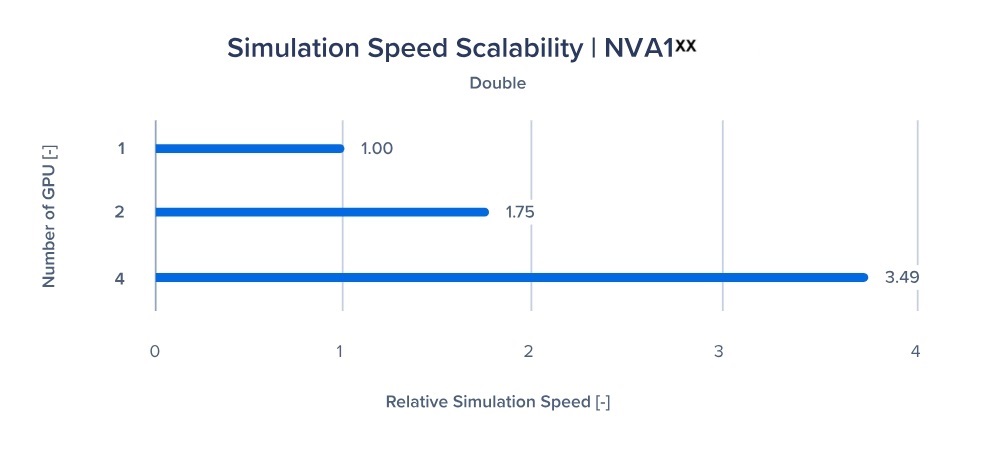
图 4
如图 3 和图 4 所示,多 GPU 部署提供了显著的可扩展性。更多的 GPU 不仅加快了模拟时间,还提供了额外的 GPU 内存,使高细胞计数模型的模拟具有无与伦比的保真度。以前需要修改以减少细胞计数以适应项目时间表的模型可以保持其高分辨率,同时仍然在可行的时间内得到解决。这些更高分辨率的仿真模型提供了更逼真的表达。
GPU 加速改造 Particleworks
通过 GPU 减少计算时间,可以进行更多的模拟迭代,最大限度地减少空闲时间,并显著提高生产率。GPU 加速计算正在改变工程师进行 CFD 和粒子动力学模拟的方式。领先的软件提供商 Ansys、西门子和达索越来越多地将 GPU 加速集成到他们的求解器中,这标志着向更快、更高效的仿真工作流程的转变。
单个 NV H1XX GPU 的性能相当于大约 900 个双精度 CPU 内核。这种性能提升允许将计算从多 CPU 集群整合到单个 GPU 加速的计算节点。
选择很重要
为您的模拟工作负载选择合适的 GPU 对于最大限度地提高性能和效率至关重要。消费级和专业级 GPU 都提供了令人印象深刻的单精度(FP32)加速,但企业级 GPU 提供了额外的鲁棒性、可扩展性和对各种工作流程的支持。
将硬件与仿真要求相匹配至关重要。对于单精度繁重的工作负载,RTX 4XYX 等消费级 GPU 是经济高效的动力源,而 H1XX 或 A1XX 等企业级 GPU 更适合多功能、内存密集型或双精度任务。跨多个 GPU 的可扩展性进一步提高了性能,为用户提供了处理最苛刻模拟的灵活性。
可扩展性
您可以通过增加部署中的 GPU 数量来提高计算能力。Particleworks 具有出色的 GPU 可扩展性,如图 3 和图 4 所示。此外,多个 GPU 也意味着您可以在各自的 GPU 上运行单独的模拟,以实现并行方法。
对于运行 CFD 模拟,利用 GPU 是显而易见的。随着 GPU 数量的增加,持续的可扩展性表明,对硬件的持续投资将带来回报,并降低总体拥有成本。保持领先于地位。
Particleworks 用户将从投资 GPU 硬件中获得巨大利益。通过利用合适的 GPU,可以大大减少模拟时间,从而实现更快的迭代和更好的结果。
光追 6XXX Ada 和光追 4XYX 是单精度 FP32 计算的绝佳 GPU 选项。对于需要 FP64 的混合精度和模拟,任何像 NV H1XX 这样的企业 GPU 都能提供关键工作负载所需的计算。
您准备好加速 Particleworks 模拟了吗?在联泰集群,我们努力为每一位客户提供最佳解决方案。无论为 Particleworks 量身定制的平台还是其他需求,都可以联系我们获取报价。我们也很乐意协助您整合各类集群部署或计算基础设施。





相关贴子
-
 基准
基准RELION GPU 3D 分类基准测试-RTX 6000 Ada、RTX 5000 Ada 和…
2024.01.01 16分钟阅读 -
 基准
基准Pacefish CFD 中 RTX PRO 6000 Blackwell 系列与 RTX 6000 Ada GPU 的基准测试
2025.09.06 49分钟阅读 -
 基准
基准AMD EPYC™ 平台优化指南——基于 GA2232 G3V2 的 HPL 性能测试
2024.12.27 22分钟阅读