
博客
GeForce RTX 4090 RELION Cryo EM 基准测试和分析
NVIDIA GeForce RTX 4090 基准测试概述

作为算力解决方案供应商,联泰集群定期提供各种 GPU 配置的参考基准测试,以指导寻求采购为其研究优化的系统的冷冻电镜(Cryogenic Electron Microscopy)科学家。在本博客中,我们使用 Relion Cryo EM 对 NVIDIA RTX 4090 性能进行了基准测试,将 GPU 运行时性能与 Total runtime 性能进行了比较。 --- 联泰集群科学工作站和服务器
软件摘要
RELION(REgularised LIkelihood OptimisationN),或 RELION,自 2012 年以来彻底改变了冷冻电镜领域。这个独立的计算机程序由 MRC 分子生物学实验室的 Scheres 实验室开发,使用贝叶斯方法通过电子冷冻显微镜数据的单粒子分析来细化大分子结构。
RELION 的开发由英国医学研究委员会(UK Medical Research Council)长期资助,并根据 GPLv2 许可证分发。这意味着任何人(包括商业用户)都可以免费下载、使用和修改 RELION。MRC 实验室只是要求,如果 RELION 在您的工作中有用,您将引用他们的论文。
RELION GPU支持摘要
随着自动化、计算能力和视觉技术的进步,冷冻电镜中使用的数据集的范围和复杂性显著增加。GPU 支持和加速对于资源管理的灵活性、防止内存限制和解决冷冻电镜的计算密集型过程(如图像分类和高分辨率细化)至关重要。
联泰集群 RTX 4090工作站系统规格:
|
节点 |
1 |
|
处理器/计数 |
1 个 AMD Ryzen Threadripper PRO 5995WX |
|
物理内核 |
64 |
|
存储器 |
256GB DDR4 内存 |
|
存储 |
3.84 TB NVMe 驱动器 |
|
操作系统 |
Ubuntu 20.04 版 |
|
CUDA 版本 |
11.8 |
|
RELION 版本 |
4.0 |
GPU基准
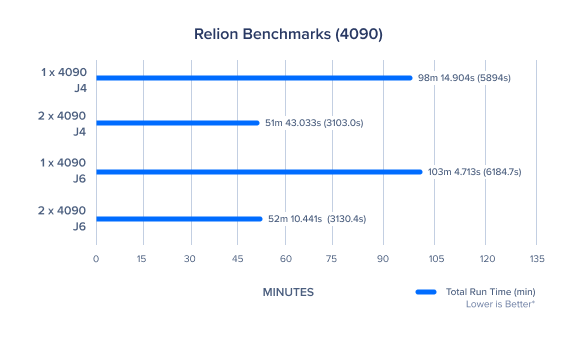
下面的基准是使用疟原虫核糖体数据集进行的 3D 分类
| > | 如果使用 RELION 中的 --scratch_dir 选项执行运行,则从命令的总运行时中减去复制到 scratch 的时间。这允许运行的比较独立于存储池的可变性。 | |
| > | GPU 时间”报告为 25 次分类迭代中的每一次在期望步骤上花费的时间,这提供了 GPU 速度的可靠快照,因为这是 RELION 中的主要 GPU 计算步骤。 | |
| > |
该图表中的基准测试是使用每个进程四个线程来执行的(--j4)。这些结果中使用的系统安装了两个 GPU 卡。 |
性能概述
> NVIDIA RTX 4090 在使用双 GPU 配置时表现出预期的改进
> RELION上NVIDIA RTX 4090 的最佳设置是使用 J4(4个线程)进行计算,用于单 GPU 配置和双 GPU 配置 2 x RTX 4090(3103.0s)比 2 x RTX-A5500(5430.51s)具有 42% 的增益
> 2 x RTX 4090(3103.0s)比 2 x RTX-3090(4788.02s)提高 35%
关于系统内存的说明
尽管建议在 RELION 的原始版本或加速版本上运行具有较小映像大小(例如200×200)的 RELION 时,至少需要 64GB 的 RAM,但 360×360 问题在具有 128GB 以上 RAM 的系统上运行得最好。对于较大映像大小上的 CPU 加速内核,建议使用内存为 256GB 或更多的系统。内存不足会导致单个 MPI 列组被终止,从而形成僵尸 RELION 作业。
MPI 设置
如果某些用户可能希望每个 GPU 运行多个 MPI 列,则需要足够的 GPU 内存。每个共享 GPU 的 MPI 从机都会增加内存的使用。然而,在这种情况下,建议为每个 GPU 运行单个 MPI 从机,以获得良好的性能和稳定的执行。
注意:具有至少两个 GPU 卡的机器最好使用 GPU 进行优化。如果您需要(或希望)在每个 GPU 上运行多个 MPI 列组,如果您只需指定多于 GPU 的列组, RELION 将尝试以有效的方式这样做。
与 RELION 的早期版本一样,可以使用--j选项运行多个线程。每个MPI进程都将启动指定数量的线程。这可能会加速计算,而不会在 CPU(RAM)或 GPU 上占用太多额外内存。
此配置的 MPI 设置使用了 2 个 MPI 列组。
关于扩展的注释
测试的 GPU 基于 Ada Lovelace。因此,向外扩展比向上扩展更有益。我们等待专业 RTX Ada Generation GPU 和 Hopper H100 GPU 进行基准测试。





相关贴子
-
 基准
基准AlphaFold2 GPU 基准测试和硬件建议
2023.12.08 10分钟阅读 -
 基准
基准GPU 加速流体和粒子模拟-使用 Enginsoft 进行 Particleworks 基准测试
2025.01.10 28分钟阅读 -
 基准
基准GROMACS 基准测试 NVIDIA RTX 4090
2023.01.13 68分钟阅读