
博客
最大限度地提高人工智能训练效率——如何选择正确的模型

快速准确地训练模型对于建立对这些工作流工具的信任非常重要。随着人工智能驱动的应用程序越来越能够执行复杂的任务,数据科学家和机器学习工程师可以探索开发创新的方法。
为了为特定用例开发最佳模型,利用适当的模型、数据集和部署可以简化人工智能开发过程并产生最佳结果。
选择最佳的模型架构对于为您的特定任务获得最佳结果非常重要。不同类型的问题需要不同的模型架构:
-
卷积神经网络(CNNs)
-
循环神经网络(RNNs)
-
Transformer 型号
-
GANs 和 Diffusion 模型
-
强化学习
-
自编码器
在选择模型架构时,请考虑您拥有的数据类型、任务的复杂性以及您拥有的资源。从更简单的模型开始,并根据需要使其更复杂,这通常是一个好主意。除了列出的 6 个清单以外,您还可以探索其他模型。
卷积神经网络(CNNs)
CNNs 是图像处理任务的理想选择,并且通过使用检测空间关系的过滤器,在提取视觉数据中的边缘、纹理和对象等模式方面表现出色。
-
用例:图像分类、目标检测
-
计算要求:由于视觉处理是 GPU 密集型的,因此 GPU 计算要求很高
-
流行架构:EfficientNet、ResNet、具有注意力机制的 CNNs
卷积神经网络已经存在了相当长的一段时间,它使用权重和参数来评估、分类和检测计算机视觉模型中的对象。随着 Transformer 架构的激增,ViTs 或视觉 Transformer 也成为了一种强有力的替代品。
循环神经网络(RNNs)
RNNs 最适合于顺序或时间依赖的数据,其中信息的顺序至关重要。它们广泛应用于语言建模、语音识别和时间序列预测等应用中,因为 RNNs 可以保留之前的输入状态,使其能够有效地捕获序列中的依赖关系。
-
用例:序列数据、时间序列分析、语音识别、预测
-
计算要求:中等至高计算要求的 GPU
-
流行架构:LSTM、GRU、bidirectional RNNs
RNNs 以前被设计为支持自然语言处理任务,但已被 BERT 和 GPT 等 Transformer 模型所取代。但 RNNs 仍然适用于高度连续的任务和实时分析,如天气建模和股票预测。
Transformer 型号
Transformer Models 彻底改变了序列数据的人工智能,特别是在自然语言处理任务中。Transformers 并行处理整个文本序列,使用自我关注来权衡不同标记、单词和短语在上下文中的重要性。这种并行性提高了它们在复杂的基于语言的任务上的性能。如果训练没有正确调整、没有在高质量数据上进行训练或训练不够,导致幻觉或误报,Transformers 确实会受到影响。
-
用例:语言处理、文本生成、聊天机器人、知识库
-
计算要求:训练需要极限的 GPU 计算能力,运行需要中等到高计算需求的 GPU
-
流行架构:BERT 和 GPT
Transformer 模型可以增强,因为它们会被提示。因此,混合专家和检索增强生成是增强高度广义人工智能模型功能的方法。
图像生成模型:Diffusion 和 GANs
Diffusion 和 GANs 用于生成新的、逼真的图像。这些图像生成模型在生成图像、视频或音乐的创意领域很受欢迎,它们也用于训练模型中的数据增强。
-
用例:通过提示生成图像、图像增强、艺术构思、3D 模型生成、图像放大、去噪
-
计算要求:GANs 可以并行化,而 Diffusion 模型是按次序的。两者都需要高 GPU 要求,特别是对于更高保真的生成。
-
流行架构:StableDiffusion、Midjourney、StyleGAN、DCGAN
扩散模型利用去噪和图像识别技术来指导模型生成有说服力的图像。数百次通过将静态模糊变成一件原创艺术品。
GANs 或一般对抗网络在迭代舞蹈中挖掘两个相互竞争的模型,一个生成器用于创建图像,一个鉴别器用于评估生成的图像是假的还是真的。连续通过将训练两个模型变得越来越好,直到生成器能够击败鉴别器。
强化学习
强化学习(RL)非常适合涉及与环境交互以实现特定目标的决策任务。RL 模型通过反复试验进行学习,使其成为机器人、游戏和自主系统应用的理想选择,在这些应用中,模型从其动作中接收反馈,以逐步提高其性能。RL 在人工智能必须随着时间的推移制定战略、平衡短期行动和长期目标的场景中大放异彩。
-
用例:游戏优化、漏洞发现、创建有竞争力的 CPU、决策制定
-
计算要求:取决于复杂性,但更多 GPU 计算会带来好处
-
流行架构:Q-Learning、DQN、SAC
你可以找到各种业余爱好者创建基于 RL 的 AI 来训练如何玩游戏的例子。强化学习模型的调整和训练需要读取行间信息,以防止人工智能学习到意外的动作。例如,在驾驶游戏Trackmania 中,人工智能从业者不允许人工智能刹车,从而在转弯时鼓励速度。他不希望人工智能学习如何成功转弯,如果这意味着需要不断刹车的话。
自编码器
自编码器是一种无监督的神经网络,旨在通过将输入数据压缩为较低维表示,然后对其进行重建来学习高效的编码。这涉及编码器压缩输入和解码器重建输入。自编码器特别适合于降维、数据去噪和异常检测等任务。它们在图像和信号处理等应用中表现出色,可以从数据中去除噪声或检测偏离常态的异常模式。此外,它们还用于生成合成数据和特征提取,使其成为各种机器学习和数据预处理任务中的通用工具。
-
用例:数据压缩、异常检测和降噪。
-
计算要求:中等计算能力;可以在中档 GPU 上运行,以获得较小的数据。
-
流行架构:普通自动编码器、变分自动编码器(VAE)。
我们开发了一个表格和一个粗略的流程图,以帮助您为您的用例选择合适的 AI 模型。这些只是建议,还有许多其他型号可供选择,但这可以让你开始。
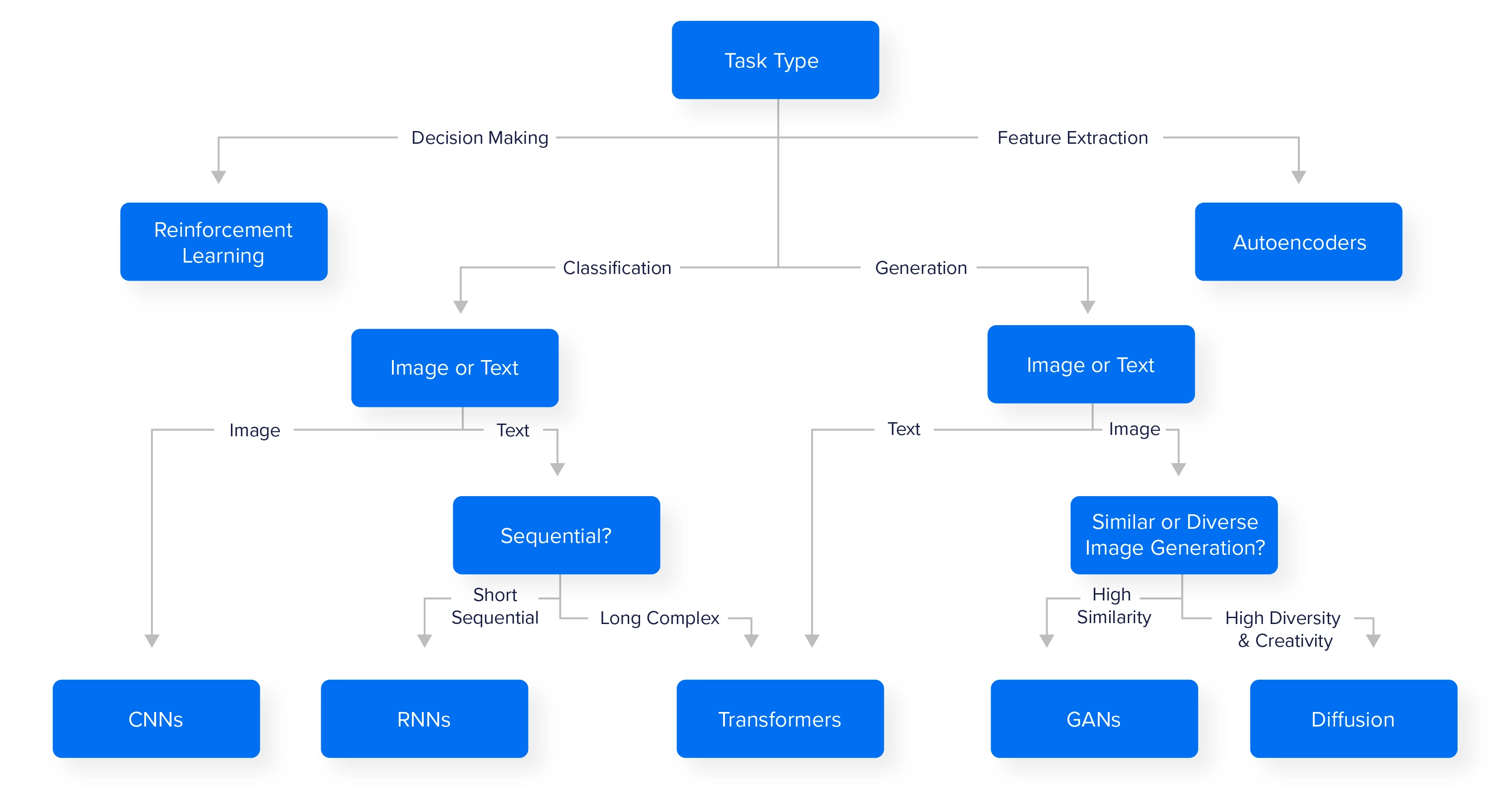
还有使用 ViTs Transformer 的 CNNs 替代品,以及可能更适合您特定用例的其他模型。我们鼓励从业者尝试不同的架构,以达到预期的效果。
但是,要高效地训练这些模型、运行探索性分析并对各种代码进行基准测试,在计算上并不便宜。高性能硬件对于更快的列车时间完成是必要的。
如果您希望升级您的计算基础设施并提高生产力水平,联泰集群将为 AI 工程师和数据科学家提供针对您用例优化的定制硬件架构。尤其是在当今飞速发展的人工智能领域,增加 GPU 算力是一项很值得的投资。





相关贴子
-
 人工智能与大模型
人工智能与大模型检索增强生成如何使 LLM 比以前更智能
2024.08.23 32分钟阅读 -
 人工智能与大模型
人工智能与大模型最大限度地提高人工智能效率——超参数调整和调节
2025.01.17 25分钟阅读 -
 人工智能与大模型
人工智能与大模型为什么 Edge AI Inferencing 对人工智能的未来至关重要
2025.05.09 22分钟阅读