
博客
三种可选的 RAG 模型——SQL、知识库和 API

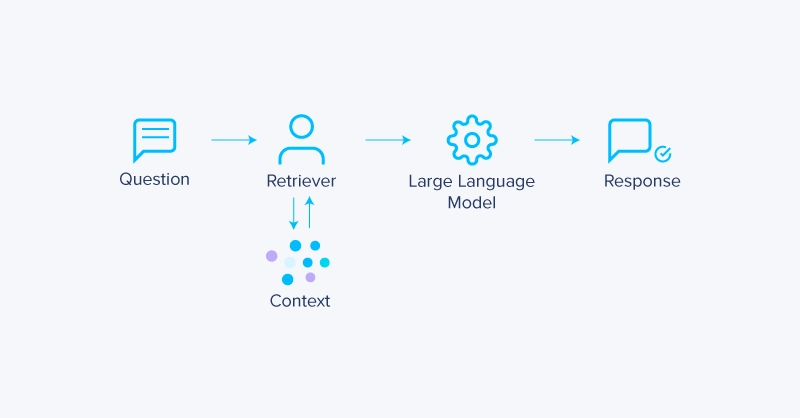
检索增强生成(RAG)已成为提高大型语言模型(LLM)响应准确性和相关性的基础技术。通过外部数据源提供上下文,RAG 减轻和减少了幻觉,增加了特定领域的上下文,并使 LLM 对需要较少可变性的企业和生产应用程序更加有用。
最常见的 RAG 系统使用向量数据库,将文本转换为高维嵌入,并使用相似性搜索为给定查询找到相关上下文。虽然在大多数情况下都是有效的,但它也有权衡。
在本博客中,我们将探讨三种高性能的 RAG 系统,它们比基于向量的 RAG 提供更好的准确性、效率或相关性——每种系统都适用于不同的用例,如挖掘结构化数据、集成实时 API 或在知识图上使用符号推理。
基于向量的检索是大多数 RAG 实现的默认骨干,它提供了一种灵活的方法,使用嵌入和相似性搜索来匹配语义相关的文档。然而,尽管这种方法具有广泛的适用性,但在需要精确或结构化推理的场景中可能会出现不足。
基于矢量的 RAG 的一些关键局限性包括:
-
语义漂移:相似性搜索可能会返回与主题相关但上下文不精确的文档。
-
大规模延迟:随着语料库的增长,检索延迟可能会增加,特别是在没有积极索引或分片的情况下。
-
缺乏结构意识:向量模糊了数据的结构,使得回答依赖于模式、层次结构或逻辑的问题变得更加困难。
尽管这些挑战在其他方法中很普遍,但它们也为专门为特定数据类型和检索需求构建的替代 RAG 方法打开了大门,提供了改进的性能和可靠性。在 RAG 中,一切基本相同,您可以通过使用数据检索系统提供上下文来增强提示。在这些其他 RAG 系统中,所有的变化都是可以提供给模型的数据类型。
这里总结了不同 RAG 架构的权衡和优势,包括传统的基于向量的 RAG,以及三种替代方法:结构化检索、API-增强和知识库 RAG。
|
RAG 类型 |
最好的 |
优势 |
弱点 |
可能的用例 |
|
基于向量的 RAG |
·通用问答 ·语义检索 |
·灵活的 ·可扩展 ·非结构化数据 |
·不精确的匹配 ·继续重新索引 |
·内部知识库 ·常见问题解答支持 ·搜索 |
|
结构化 RAG |
·企业数据 ·规范场 |
·确定性 ·架构意识 ·低幻觉 |
·需要特定领域的查询逻辑 ·复杂整合 |
·生成报告 ·CRM 查询 ·病历 |
|
API-增强 RAG |
·实时数据 ·挥发性信息 |
·实时结果 ·减少索引维护 |
·取决于 API ·较高的延迟 |
·服务聊天机器人 ·物联网设备(相机,传感器等) ·天气或市场监视器 |
|
基于知识的 RAG |
·逻辑沉重 ·合规性 |
·精确的 ·可以解释 ·基于规则的域 |
·复杂的实现 ·可伸缩性 |
·代码文档 ·推荐系统 ·决策 |
结构化检索 RAG(SQL/表格 RAG)
结构化检索 RAG 将 LLM 与关系数据库或结构化表格源(如 SQL 表和 CSV 文件)集成在一起。该系统不依赖于向量相似性,而是制定精确的查询来获取准确的数据值,确保了较高的事实准确性和可追溯性,使其成为企业和受监管环境的理想选择。优点包括:
-
确定性结果:查询根据定义的模式和约束返回精确匹配。
-
模式感知:模型理解表结构、字段名和实体之间的关系。
-
降低幻觉风险:输出基于可验证的结构化数据。
这种方法在金融、医疗保健和制造业尤其有效,因为事实精度和数据沿袭至关重要。
API-增强型 RAG
作为模型推理过程的一部分,API 增强的 RAG 通过调用 API 实时检索外部信息。该模型不依赖预先摄入的文档存储,而是通过实时 API 端点访问动态数据,如当前股价、天气状况或物联网设备。你甚至可以建立一个谷歌搜索 API。优点包括:
-
访问实时数据:非常适合时间敏感或频繁变化的信息。
-
无需静态索引:减少维护开销,避免过时的上下文。
-
灵活的集成:轻松连接到跨域的专有或公共服务。
这种方法通常用于在动态环境中运行或需要最新精度的基于LLM的代理和助手。
基于知识的 RAG(符号 RAG)
知识库 RAG 系统将 LLM 与结构化知识表示相结合,如知识图、本体或基于逻辑的规则引擎。这些系统不是依赖于模糊相似性,而是基于显式关系和逻辑推理检索事实或实体,从而实现了高度的可解释性和准确性。优点包括:
-
可解释性:检索基于定义的实体、关系和规则,提供完全的可追溯性。
-
准确性:非常适合法律、技术或科学准确性是强制性的用例。
-
领域建模:能够以结构化形式捕获特定领域的逻辑。
这种方法在法律、合规或研究等领域尤其有价值,在这些领域,可解释性和正确性比知识广度更重要。
选择最佳的 RAG 架构取决于数据的性质和可靠的输出。考虑您在这些关键维度上的具体要求:
|
数据结构 |
数据及时性 |
|
|
向量 RAG |
非结构化 |
静止的 |
|
结构化的 DB RAG |
结构 |
静止的 |
|
API RAG |
两个都 |
即时的 |
|
知识库 RAG |
结构 |
静态和实时 |
-
数据类型:非结构化文本使用向量 RAG;在处理表格、基于图形或逻辑驱动的数据时,使用结构化或符号 RAG。
-
实时要求:当信息频繁变化或需要精确到分钟时,API-Auged-RAG 是最好的。
-
精度和可追溯性:当需要确定性、可验证的答案时,结构化和符号化的 RAG 会大放异彩。
-
实现复杂性:基于向量的 RAG 最初更容易设置,而替代方案可能需要特定领域的集成和逻辑处理。
最终,混合方法——结合多种检索方法——通常可以提供最好的结果,使系统能够根据查询类型或所需的输出质量进行智能调整。
任何任务的挑战都是选择合适的工具来完成这项工作。检索增强生成影响了 LLM 如何用知识进行定制。在提示中为AI提供上下文可以增强其能力。基于向量的 RAG 是广泛使用案例的多功能选择,但当精度、上下文控制或实时访问至关重要时,结构化、API增强和知识库 RAG 等替代方法可以提供优异的结果。
为了进一步提高你的人工智能实现,关键在于硬件、网络和存储速度。与联泰集群的工程师联系,配置您理想的计算基础设施,为您的工作负载提供动力。我们的解决方案从即用型 GPU 工作站、可配置服务器到全机架集成集群全场景覆盖。





相关贴子
-
 技术分享
技术分享AlphaProteo-DeepMind 最新的蛋白质折叠模型
2025.02.14 33分钟阅读 -
 技术分享
技术分享从‘专用’到‘真共享’:高校算力资源孤岛破冰全纪实
2025.05.09 37分钟阅读 -
 技术分享
技术分享BERT 转换器原理详解
2025.11.21 60分钟阅读